When I first started focusing on long-tail keywords, I assumed great content alone would do the trick. But despite targeting ultra-specific queries with low competition, I wasn’t getting the expected traffic.
That’s when I realized the issue wasn’t with my content but with crawlability.
Crawlability refers to how easily search engine bots can navigate and access the pages on your website. If your pages aren’t crawlable, they’re practically invisible to Google, no matter how well-optimized your long-tail keywords are.
In this blog, I’ll explain why crawlability is non-negotiable if you’re serious about ranking for long-tail search terms.
I’ll also share how I audit crawl issues, the tools I trust, and what worked to get my long-tail content discovered and indexed.
What Is Website Crawlability and Why Do I Care About It?
Before I fixed my crawl issues, I didn’t even realize Google wasn’t discovering some of my best pages. That’s when I learned what crawlability means: it’s the ability of search engine bots, such as Googlebot, to access, navigate, and understand the structure of my website.
If a crawler can’t reach a page, it won’t index it. And if it doesn’t index it, that page has zero chance of appearing in search results, regardless of how good the content or how well I optimize my keywords.
I care about crawlability because it directly affects which pages search engines see. It’s like having a library full of valuable books but locking the door so no one can read them.
I’ve seen firsthand how fixing crawl-related barriers, such as broken links, blocked pages in robots.txt, or poor internal linking, led to an almost immediate increase in long-tail keyword impressions.
Crawlability is often overlooked, but for me, it’s the foundation of any successful SEO strategy, especially when targeting low-volume, high-intent long-tail keywords.
Read More On: How to Find Entities for SEO Optimization
Why Long-Tail Keywords Are Worth Targeting
When I shifted my focus from broad, high-competition keywords to more specific long-tail keywords, I saw a vast improvement in traffic and conversion rates. These keywords may have lower search volumes, but they attract highly targeted visitors much closer to taking action.
For example, instead of trying to rank for a generic term like “SEO tools,” I targeted phrases like “best SEO tools for WordPress bloggers” or “affordable link-building tools for startups.”
These long-tail queries brought in readers looking for exactly what I offered and they stuck around longer, explored more pages, and even reached out.
What I love most about long-tail keywords is that they enable me to compete in saturated markets without needing to build hundreds of backlinks or outrank established big-name sites.
With solid content and proper crawlability, I can establish my niche and start ranking more quickly.
Read more on: Will AI Replace SEO?
While they may not always make headlines in SEO reports, long-tail keywords are my secret weapon for driving meaningful traffic with higher intent.
The Link Between Crawlability and Long-Tail Keyword Visibility
I used to assume that if I published great content, Google would automatically find and rank it. But I learned the hard way: even the best long-tail content stays invisible if your site isn’t crawlable.
Long-tail keywords often live deep in your site within blog posts, product pages, or niche guides. These aren’t usually your homepage or top-level categories.
That’s why crawlability becomes even more critical. Those pages won’t get indexed if Googlebot can’t access them due to poor internal linking, orphan content, or misconfigured robots.txt rules.
And if they’re not indexed, they won’t rank. Simple as that.
One of my long-tail optimized blog posts sat in limbo for months with no impressions or traffic until I realized it wasn’t linked from anywhere else on the site.
Once I added internal links and updated the sitemap, it started showing up for multiple low-competition queries.
That’s when it hit me: improving crawlability is like allowing Google to enter the room where your long-tail content lives.
Read More On: 10 Best SEO Resellers: Reviewed by Experts
Crawlability Issues That Cost Me Long-Tail Traffic
I’ve made my share of crawlability mistakes and paid the price in lost traffic, especially on pages targeting long-tail keywords. Here are the most common issues I encountered (and fixed):
a. Orphan Pages
I had several blog posts with excellent long-tail keyword optimization, but they weren’t linked from anywhere else on the site.
Result: Google never discovered them.
b. Broken Internal Links
Some internal links pointed to outdated or deleted URLs. This broke the crawl path and wasted crawl budget.
It also negatively impacts user experience, which in turn affects rankings indirectly.
c. Overly Deep URL Structures
Pages buried 4 or 5 levels deep took a long time to get crawled. Google prefers a flatter architecture.
Fixing this improved both speed and indexation.
d. Blocked by Robots.txt or Meta Noindex
I mistakenly blocked important folders in my robots.txt and added noindex them to live content during testing, but I forgot to revert them.
That was a major crawl blocker until I caught it during an audit.
e. Outdated XML Sitemaps
Some of my sitemaps were missing key URLs or still had 404 links.
Google relied heavily on my sitemap to discover long-tail content, so I had to keep it clean and current.
Each of these crawl issues quietly sabotaged my long-tail keyword strategy. And the worst part? I didn’t realize it until I dug into crawl stats in Google Search Console.
How I Improve My Site’s Crawlability (Checklist)?
To consistently rank for long-tail keywords, I’ve built a habit of regularly auditing crawl health. Below is a simple checklist I follow to keep my site crawl-friendly and Googlebot-happy:
| Issue | Fix I Use |
|---|---|
| Orphan Pages | Added internal links from related blog posts |
| Broken Internal Links | Ran Screaming Frog crawl and fixed errors |
| Deep URL Structure | Flattened site architecture to <3 levels |
| Blocked in Robots.txt | Whitelisted important directories |
| Meta Noindex on Key Pages | Reviewed meta tags and removed accidental blocks |
| Outdated XML Sitemap | Auto-generate sitemap with Rank Math plugin |
| Slow Crawl Rate | Improved page load speed & reduced redirects |
| Canonical Tag Conflicts | Fixed misused canonicals pointing elsewhere |
This checklist helped me recover dozens of underperforming pages that were optimized well but hidden from crawlers.
How Better Crawlability Helped Me Rank for Long-Tail Keywords?
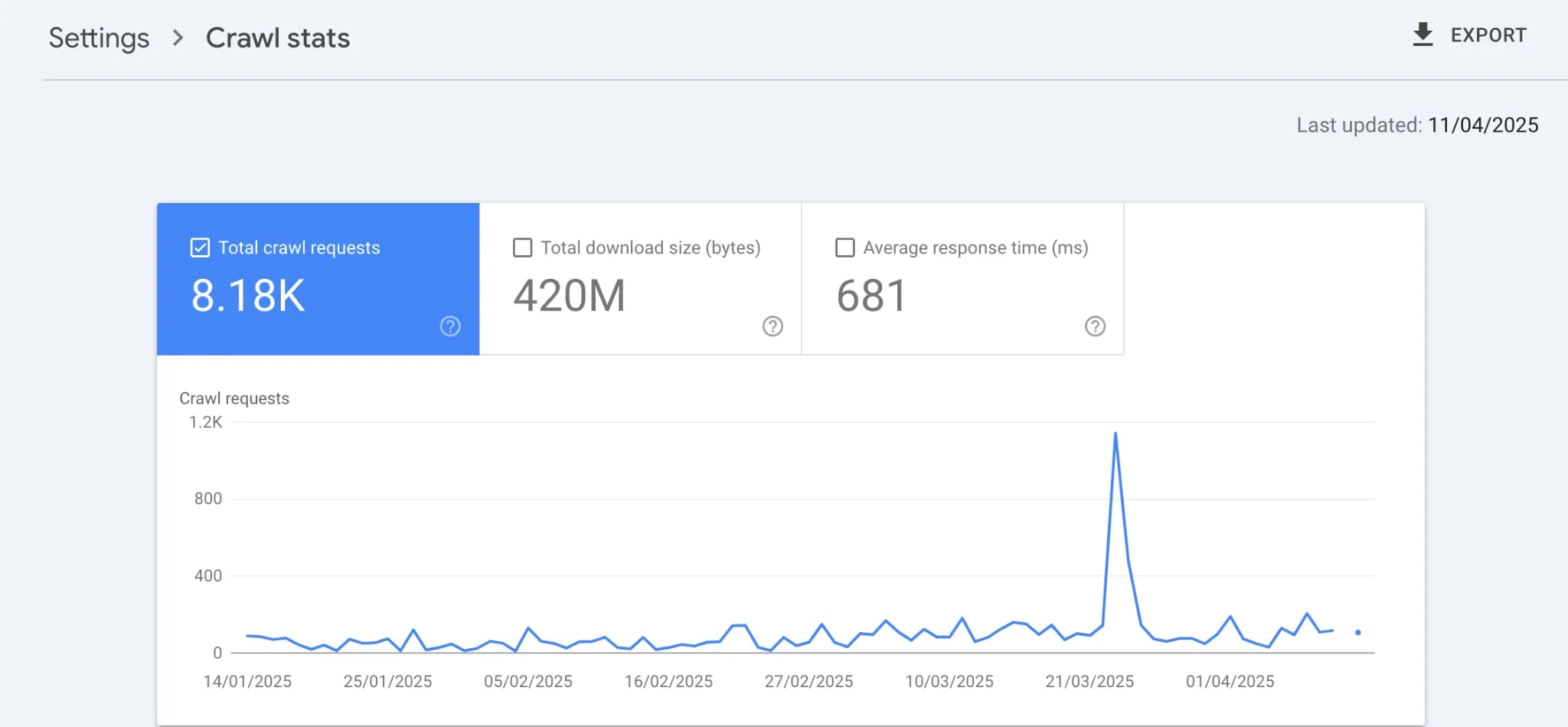
After fixing some of the crawl issues I mentioned earlier, I noticed significant changes in my Search Console metrics, especially for long-tail queries.
One clear indicator was the spike in crawl activity, as shown in the chart above. Googlebot became more active around late March 2025, which directly aligned with the improvements I made:
- I updated my XML sitemap and resubmitted it.
- I added internal links to orphan pages.
- I fixed the redirect chains and unnecessary
noindextags.
Within a week, pages that had zero impressions for months started appearing for ultra-specific queries like:
- “Seo audit checklist for small business”
- “Long-tail keyword strategy 2025”
- “Crawl budget optimization for WordPress sites”
Read more on: 50+ Inspirational and Business Quotes That Motivate You.
These weren’t just impressions; they came with clicks, thanks to low competition and high intent.
The takeaway? Improving crawlability doesn’t just make your site technically better. It unlocks SEO potential that is already waiting to be discovered.
Tools I Use to Monitor Crawlability & Long-Tail Keyword Ranking
Over time, I’ve developed a small yet powerful toolkit that enables me to monitor crawl health and the performance of my long-tail keywords. These tools help me stay proactive, not reactive, with technical SEO.
a. Google Search Console
My go-to for crawl stats, index coverage, and performance insights.
- I regularly check the Crawl Stats report to monitor spikes or drops.
- The Performance tab shows me which long-tail queries are gaining impressions and clicks.
b. Screaming Frog SEO Spider
This tool is a robust crawl simulation.
- I use it to identify broken links, orphan pages, crawl depth, and duplicate content.
- Helps me visualize site architecture and spot crawl inefficiencies.
c. Ahrefs / Semrush
While these are primarily backlink and keyword tools, they’re fantastic for:
- Tracking long-tail keyword rankings over time.
- Finding keyword cannibalization issues.
- Monitoring crawl anomalies, such as high crawl frequency on irrelevant pages.
d. JetOctopus / Sitebulb (Advanced)
These tools are incredible if I want deeper crawl analysis or JavaScript rendering reports.
- JetOctopus is especially helpful for large sites.
- Sitebulb provides visual crawl maps, which are great for spotting problems fast.
e. Rank Math SEO Plugin (for WordPress)
This helps me maintain updated XML sitemaps and monitor indexation settings directly in WordPress.
- I can quickly fix noindex tags, canonical issues, and schema problems.
What Happens When Crawlability Is Ignored?
I learned the hard way that ignoring crawlability can silently undermine your SEO efforts, especially when you’re targeting long-tail traffic.
At one point, I had dozens of blog posts that were well-optimized, keyword-rich, and even earning a few backlinks, but they wouldn’t rank.
Here’s what I experienced when crawlability was an afterthought:
a. Zero Impressions Despite Great Content
I targeted long-tail keywords like “technical SEO checklist for e-commerce,” a low-volume, high-intent query. However, weeks went by with zero impressions in Google Search Console. The problem? The page was buried five clicks deep and had no internal links.
b. High Crawl Stats, Low Indexation
Googlebot wasted its crawl budget on unimportant URLs, such as tag archives, paginated comments, and outdated category pages. My money pages weren’t even in the sitemap.
Result: Google crawled the wrong pages and ignored the important ones.
c. No Visibility for Pages with Backlinks
I even had a few pages with natural backlinks from industry forums, but they weren’t getting indexed. Why? They were disallowed in my robots.txt by mistake.
Moral of the story: Backlinks help, but only if the page can be crawled and indexed.
d. Slow Performance on New Posts
I’d publish something valuable, but it wouldn’t get indexed for days or weeks. My sitemap wasn’t updating correctly, and I had duplicate content issues and confusing crawl paths.
Ignoring crawlability is like building a store without an entrance; you may have great products inside, but no one’s coming in. I now treat crawlability as the first step in every SEO process, especially for content targeting long-tail keywords.
Read more on: Auto Inventory Ads Keyword Tips for Dealerships
How I Structure My Site for Crawl Efficiency?
When I realized crawlability was holding back my long-tail rankings, I didn’t just fix isolated issues, I rethought the entire layout of my site architecture. The goal? Make it easy for search engines (and users) to find, follow, and understand every important page.
Here’s exactly how I structure my site today for maximum crawl efficiency:
a. Flat Site Architecture
I aim for a structure where the most important pages are no more than 3 clicks from the homepage. This helps search engines crawl deeper without getting lost in subfolders or pagination loops.
b. Siloing by Topic Cluster
Instead of scattering blog posts everywhere, I organize them around central themes or “pillar” pages.
For example:
/seo/technical-seo-guide//seo/technical-seo-guide/crawlability-checklist//seo/technical-seo-guide/xml-sitemaps-tips/
This helps reinforce topical relevance and makes crawl paths more predictable.
c. Breadcrumbs and Internal Linking
Breadcrumbs aren’t just for UX; they give crawlers extra context and hierarchy. I also contextually place internal links within blog content to guide bots to related posts, especially newer ones.
d. Consistent URL Structure
No random parameters, no messy folder nesting. I keep URLs clean, keyword-rich, and easy to navigate. For example:
- Use:
/blog/seo-crawlability-tips/ - Avoid:
/index.php?id=23&page=seo-2025
e. Updated HTML + XML Sitemaps
I use both:
- HTML sitemap for users, linked in the footer.
- Dynamic XML sitemap auto-managed by Rank Math, submitted to Search Console regularly.
Why Crawl Budget Matters (Even for Small Sites)?
I used to believe that crawl budget limitations were something only massive enterprise websites had to worry about.
But after optimizing a few dozen blog posts for long-tail keywords, I noticed that crawl budget limitations can quietly limit visibility even on smaller sites.
Here’s what I learned:
a. Crawl Budget Isn’t Just About Size
Google allocates crawl resources based on a site’s authority, structure, and health rather than just the number of pages it has. Even with a 100-page site, if Googlebot encounters too many redirects, broken links, or irrelevant parameters, it may slow down or skip important pages.
b. Low-Value Pages Waste Resources
Things like:
- Thin content.
- Tag and category archives.
- Paginated comments.
Can eat up the crawl budget. I had to prune or block these using robots.txt andnoindextags to ensure Google focused on my money pages targeting long-tail terms.
c. Fresh Long-Tail Content Wasn’t Being Crawled Fast Enough
When I published new articles targeting long-tail keywords, they often took days to be crawled. Cleaning up my crawl paths and updating my sitemap regularly made new content appear in search results much faster.
d. Signs Crawl Budget Might Be an Issue (Even for You)
- GSC shows “Discovered – currently not indexed” warnings.
- Crawl stats show wide gaps between fetch attempts.
- Some pages never appear in
site:yourdomain.comsearches.
My Internal Linking Strategy for Long-Tail SEO
If there’s one tactic that consistently boosts crawlability and rankings for long-tail keywords, it’s internal linking. Over time, I’ve developed a simple but powerful system that ensures Googlebot (and users) can easily discover my long-tail content.
Here’s precisely how I do it:
1. Link from High-Traffic Pages to Targeted Long-Tail Posts
Whenever I publish a new post targeting a long-tail keyword, I link to it from:
- My homepage (if relevant).
- High-ranking pillar posts.
- Related articles already indexed.
This gives new pages an initial crawl boost and directs link equity to the most relevant locations.
2. Use Descriptive Anchor Text
I avoid generic links like “click here”. Instead, I use exact-match or semantically relevant anchor text to reinforce topical relevance for search engines. For example:
- Use: “Technical SEO tips for beginners”.
- Avoid: “This article explains it”.
3. Update Older Posts Regularly
Every few months, I revisit older blog posts and look for opportunities to:
- Link to newer content
- Add updated anchor text
- Fix broken or redirected links
This keeps my internal link network fresh and compelling.
4. Leverage “Hub” Pages for Topical Authority
I maintain category-level hub pages (like “/seo/technical-seo/”) that link to multiple related long-tail blog posts.
This helps Google understand the hierarchy and context of each keyword variation within a broader topic.
5. Don’t Overdo It
I aim for 3–5 meaningful internal links per post. Overstuffing can dilute value and confuse bots.
Step-by-step SEO strategy for clinic websites
Difference Between Crawlability and Indexability (Explained Simply)
At first, I used to confuse crawlability and indexability, but understanding the difference helped me address many SEO blind spots.
Here’s how I simplify it for myself:
Crawlability = Access
Crawlability refers to whether Googlebot can access a page.
If your page isn’t linked internally, blocked by robots.txt, or buried too deep in your site structure, it’s not crawlable.
If Google can’t get to your page, it won’t know it exists.
Indexability = Permission
Even if a page is crawlable, that doesn’t guarantee it’ll be indexed. Indexability refers to whether Google can include a page in its search index.
Things that can affect indexability:
noindexmeta tags- Canonical tags pointing elsewhere
- Duplicate content
- Thin content with low value
If you tell Google not to index it or provide reasons for it to skip, it will.
A Quick Analogy
Think of Googlebot like a delivery person:
- Crawlability = You left the gate open so they can walk up to your door
- Indexability = You let them inside the house to drop off the package
If either part is blocked, your SEO delivery fails.
Now that I understand the distinction, I always ask two questions for every new page:
- Can Google crawl this?
- Would Google want to index this?
Long-tail keyword success is likely to follow when the answer is yes to both.
Lastly
If there’s one thing I’ve learned, it’s this: you can’t rank what Google can’t crawl.
I used to focus all my energy on keyword research and content writing, especially for long-tail keywords, but I didn’t see results until I fixed my crawlability issues.
Everything changed once I addressed broken links, optimized internal linking, and cleaned up my sitemap. My content began to get indexed faster, and previously buried long-tail pages started ranking. Traffic followed.
If crawlability concerns your site, you may consider hiring a reputable technical SEO agency to address the issue at its root.
So if you’re working to target long-tail keywords, don’t let crawlability sabotage your efforts behind the scenes.
Make it a habit to regularly audit your site’s crawl health; it’s one of the easiest, highest-ROI fixes in SEO.
Read more on:
- Will AI Kill SEO?
- Why Stewart Vickers is the Best SEO in the World?
- Google’s Recent Deindexing Wave – How to Respond?
- Rewriting Rules: Bold World of T-Mobile Marketing
Crawlability refers to how easily search engine bots can access and navigate my website. If a page isn’t crawlable, Google won’t even see it, so it can’t be ranked, regardless of the quality of the content.
Long-tail keywords typically reside deeper within the site, inside blog posts, guides, or niche landing pages. If those pages aren’t crawlable, they’ll never get indexed. I’ve seen this firsthand, and fixing crawlability is what got those pages ranking.
I utilize tools such as Google Search Console and Screaming Frog. If I see “Discovered – currently not indexed” or orphan pages with no internal links, it’s a red flag. Also, if a page doesn’t appear in a site: I know it’s not indexed yet, so I’ll search.
Yes, and that used to confuse me. Just because Google can reach a page doesn’t mean it will index it. Things like noindex Low-quality content, or improper canonicals, can prevent a page from being added to the index.
My go-to tools are Google Search Console, Screaming Frog, and Rank Math, specifically for WordPress sites. I also use Ahrefs to track long-tail keyword visibility and crawl stats together.
Internal links act like signposts for Googlebot. I ensure each long-tail content page has 2–5 internal links from related posts. That’s how I ensure that they’re found and crawled quickly.
Absolutely. Once I resolved the crawlability issues, many long-tail posts began ranking within days, without requiring new backlinks. Better crawlability means better discovery, faster indexing, and higher chances of ranking.
Would you like me to review your site?
Book a free SEO crawl audit call, and I’ll help you uncover what’s stopping Google from ranking your best content.