
Laatst bijgewerkt op 6 april 2026
AI-zoekmachines veranderen de manier waarop mensen informatie vinden.
In plaats van trefwoorden in te typenGoogle, vragen gebruikers nu ChatGPTGemini en Perplexity stellen directe vragen.
En ze krijgen direct antwoord.
Geen blauwe links.
Niet scrollen.
Geen tien resultaten per pagina.
Die verschuiving dwingt SEO Om verandering teweeg te brengen en een nieuw perspectief te creëren waarmee experts zich kunnen oriënteren.
Tegenwoordig rangschikken zoekmachines pagina's niet meer alleen.
Ze genereren antwoorden.
En achter die antwoorden schuilen grote taalmodellen (LLM's) die bepalen welke websites te vertrouwen, te citeren en aan te halen zijn.
Deze behoefte aan AI-vriendelijke optimalisatie leidt tot een nieuwe discipline: LLM SEO.
LLM SEO optimaliseert uw website Zo kunnen AI-systemen uw content ontdekken, begrijpen en gebruiken als bron voor door AI gegenereerde antwoorden.
Als uw website niet zichtbaar is voor LLM's, verliest u verkeer voordat rankings er toe doen.
In deze gids leert u:
- Wat LLM SEO is en hoe het werkt
- Hoe AI-zoekmachines websites vinden en rangschikken
- Wat ChatGPTGemini en Perplexity zoeken in bronnen
- Hoe optimaliseer je je content voor AI-zoekresultaten?
- Hoe je verkeer vanuit LLM's kunt volgen
Aan het eind weet je precies hoe je je website kunt voorbereiden op de volgende fase van zoekmachineoptimalisatie.
Lees meer over: Beste AI-videogeneratoren in 2026 (top 7 vergeleken)
Wat is LLM SEO?

LLM SEO staat voor Groot taalmodel zoekmachineoptimalisatie.
Het is het proces van het optimaliseren van je website, zodat AI-systemen zoals ChatGPT, Google Gemini, Perplexity en Google SGE het volgende kunnen doen:
- Ontdek je content
- Begrijp het correct
- Beschouw het als een betrouwbare bron.
- Verwijs ernaar in door AI gegenereerde antwoorden.
Bij traditionele SEO is het doel om pagina's hoog te laten scoren in Google.
Bij LLM SEO is het doel anders:
Jouw doel is om de bron te worden die de AI kiest om te citeren.
In plaats van te strijden om kliks, strijd je om citaties.
In plaats van links te rangschikken, optimaliseer je antwoorden.
Een eenvoudige definitie van LLM SEO
Dit is de eenvoudigste manier om het te definiëren:
LLM SEO optimaliseert content zodat grote taalmodellen deze kunnen ophalen, begrijpen en gebruiken als bron in AI-zoekresultaten.
Dit bevat:
- Inhoud zo formatteren dat machines deze gemakkelijk kunnen verwerken.
- Gebruikmaken van gestructureerde data en schema's
- Het opbouwen van autoriteit op een bepaald onderwerp en merksignalen.
- Het publiceren van duidelijke, feitelijke en goed georganiseerde antwoorden.
Als een AI-systeem je pagina niet begrijpt, zal het die niet gebruiken.
Wat betekent "LLM" in SEO?
LLM staat voor Groot taalmodel.
Dit zijn AI-systemen die getraind zijn om mensachtige tekst te lezen, te begrijpen en te genereren.
Voorbeelden hiervan zijn:
- ChatGPT (OpenAI)
- Google Tweelingen
- Claude (Antropisch)
- Perplexiteit AI
Wanneer deze systemen een vraag beantwoorden, surfen ze niet op het web zoals mensen dat doen.
Ze halen documenten uit zoekindexen, beoordelen ze, halen relevante passages eruit en genereren vervolgens een antwoord op basis van die bronnen.
Dat zoek- en selectieproces is waar LLM SEO zich op richt.
Lees meer over: Beste AI-videogeneratoren in 2026 (top 7 vergeleken)
Waarvoor LLM SEO optimaliseert
Traditionele SEO optimaliseert voor:
- Rankings
- Click-through tarieven
- Verkeer
LLM SEO optimaliseert voor:
- Bronselectie
- Citaten en bronvermeldingen
- Entiteitsherkenning
- Relevantie van het antwoord
- Vertrouwen en gezagssignalen
In veel zoekresultaten die door AI zijn gegenereerd, klikken gebruikers nooit op een link.
Ze lezen het antwoord en gaan verder.
Dat betekent dat de meest waardevolle positie in AI-zoekresultaten niet "positie #1" is.
Zijn:
Omdat het de website is die de AI voldoende vertrouwt om te citeren.
Hoe LLM SEO verschilt van traditionele SEO
LLM SEO en traditionele SEO zijn aan elkaar verwant.
Maar dat zijn niet dezelfde dingen.
Traditionele SEO is ontwikkeld voor zoekmachines die links rangschikken.
LLM SEO is ontwikkeld voor systemen die antwoorden genereren.
Dat verschil verandert alles.
Pagina's rangschikken versus bronnen selecteren
Bij traditionele SEO is het doel eenvoudig:
Zorg ervoor dat uw pagina zo hoog mogelijk scoort in Google.
Gebruikers bekijken de resultaten.
Ze kiezen een link.
Het klikt.
In LLM SEO is er geen lijst met links.
De AI selecteert een klein aantal bronnen, haalt er informatie uit en genereert één antwoord.
Als uw pagina niet is geselecteerd, is deze onzichtbaar.
Je strijdt niet om de eerste plaats.
Je doet mee aan een wedstrijd om te worden een van de weinige bronnen die de AI vertrouwt.
Trefwoorden versus entiteiten
Traditionele SEO is gebaseerd op zoekwoorden.
Je optimaliseert voor:
- Exacte trefwoorden
- Zoekvolume
- Trefwoord moeilijkheid
LLM SEO is entiteitsgericht.
AI-systemen hechten meer waarde aan:
- Onderwerpen en concepten
- Merken en auteurs
- Relaties tussen entiteiten
In plaats van te vragen: "Bevat deze pagina het zoekwoord?"
LLM-studenten vragen:
Is deze website een betrouwbare bron over dit onderwerp?
Daarom zijn thematische autoriteit en entiteits-SEO veel belangrijker bij AI-zoekopdrachten.
Backlinks versus merkvermeldingen
Backlinks zijn nog steeds belangrijk.
Maar in LLM SEO, Merkvermeldingen en citaties wegen net zo zwaar mee..
AI-systemen leren autoriteit van:
- Vermeldingen op internet
- Uitgeversreferenties
- Kennis grafieken
- Auteursprofielen
Een website die veelvuldig wordt genoemd, zelfs zonder links, presteert vaak beter in AI-antwoorden dan een website die alleen backlinks bevat.
Vertrouwen is niet langer alleen een maatstaf voor verbindingen.
Het is een signaal dat de reputatie beïnvloedt.
Klikken versus citaties
Traditionele SEO-metingen gebruiken de volgende criteria voor succes:
- Rankings
- Verkeer
- Klikfrequentie
LLM SEO hanteert een andere maatstaf voor succes.
De belangrijkste meetwaarden zijn:
- Hoe vaak uw site wordt geciteerd
- Hoe vaak komt uw merk voor in AI-antwoorden?
- Of uw content nu als bron wordt gebruikt of niet.
In veel gevallen bezoeken gebruikers uw website nooit.
Maar uw merk beïnvloedt hen nog steeds via het AI-antwoord.
Zichtbaarheid komt nu vóór de klik.
Pagina-optimalisatie versus antwoord-optimalisatie
Traditionele SEO richt zich op:
- Titel tags
- Metabeschrijvingen
- Plaatsing van zoekwoorden
LLM SEO richt zich op:
- Duidelijke definities
- Gestructureerde opmaak
- Directe antwoorden
- Lijsten, tabellen en samenvattingen
AI-systemen geven de voorkeur aan content die:
- Beantwoordt vragen snel
- Gebruikt eenvoudige taal
- Is logisch georganiseerd
- Bevat feitelijke, verifieerbare informatie.
Hoe makkelijker je content te extraheren is, hoe groter de kans dat deze gebruikt wordt.
Een snelle vergelijking
Traditionele SEO:
- Ranglijstpagina's
- Optimaliseert zoekwoorden
- Concurreert om klikken
- Richt zich op backlinks
- Verkeersmetingen
LLM SEO:
- Selecteert bronnen
- Optimaliseert entiteiten
- Concurreert om citaties.
- Richt zich op vertrouwen en citeert
- Meet de zichtbaarheid
LLM SEO vervangt traditionele SEO niet.
Het bouwt daarop voort.
De beste strategie in 2026 is niet kiezen voor het een of het ander.
Het is een combinatie van beide.
Hoe werken AI-zoekmachines?
AI-zoekmachines werken niet zoals de traditionele crawler van Google.
Ze scannen niet zomaar pagina's en rangschikken links.
In plaats daarvan combineren ze drie systemen:
- Trainingsdata
- Live zoekresultaten
- Antwoordgeneratie
Inzicht in dit proces vormt de basis van LLM SEO.
Stap 1: Trainingsgegevens (Hoe LLM's een taal leren)
Grote taalmodellen worden getraind op enorme datasets.
Deze omvatten:
- Openbare websites
- Common Crawl-archieven
- Boeken en documentatie
- Gelicentieerde uitgeversinhoud
- Forums en technische hulpmiddelen
Deze training leert het model het volgende:
- Taalpatronen
- Feiten en concepten
- Hoe de onderwerpen met elkaar samenhangen
Maar trainingsdata hebben een grote beperking.
Het is vaak maanden of jaren oud.
Dat betekent dat LLM's niet uitsluitend op trainingsdata kunnen vertrouwen voor nieuwe informatie.
Stap 2: Live zoeken en ophalen (Hoe AI actuele gegevens verkrijgt)
Moderne AI-systemen maken gebruik van realtime gegevensopvraging.
Wanneer een gebruiker een vraag stelt, voert het systeem de volgende vragen uit:
- Zoekmachine-indexen (Bing, Google SGE)
- Eigen ontwikkelde crawling-pipelines
- API's en partnerschappen van uitgevers
Deze stap wordt genoemd ophalen.
Het systeem haalt een reeks relevante documenten van het internet.
Deze documenten vormen de mogelijke bronnen voor het antwoord.
Als uw website niet vindbaar is in deze indexen, wordt deze nooit in overweging genomen.
Dit is waar klassieke SEO van pas komt.
Stap 3: Rangschikking en passagekeuze
Na het ophalen van de documenten gebruikt de AI niet elk document.
Het beoordeelt elk item op basis van:
- Relevantie voor de vraag
- Autoriteit van de bron
- Versheid
- Inhoud kwaliteit
Slechts een klein aantal pagina's overleeft deze fase.
Het systeem haalt uit die pagina's specifieke passages.
Deze passages vormen het ruwe materiaal voor het uiteindelijke antwoord.
Stap 4: Antwoordgeneratie
In de laatste stap genereert het LLM een antwoord.
Het combineert:
- De vraag van de gebruiker
- Opgehaalde passages
- Het is aangeleerde kennis.
Het resultaat is een antwoord in natuurlijke taal.
Soms geeft het systeem bronvermeldingen weer.
Soms is dat niet het geval.
Maar in elk geval zijn het slechts enkele factoren die de uitkomst beïnvloeden.
Waarom dit belangrijk is voor SEO
Deze workflow verklaart waarom LLM SEO anders is.
Om in de AI-antwoorden te verschijnen, moet uw website aan de volgende voorwaarden voldoen:
- Zorg dat je vindbaar bent in zoekmachines.
- Worden geselecteerd tijdens het ophalen
- Scoor hoog tijdens de ranking.
- Bevat extracteerbare passages
Als je bij een van deze stappen een fout maakt, wordt je content verwijderd.
Je verliest je positie niet.
Je verliest het zicht.
Hoe ChatGPT, Gemini en Perplexity websites vinden
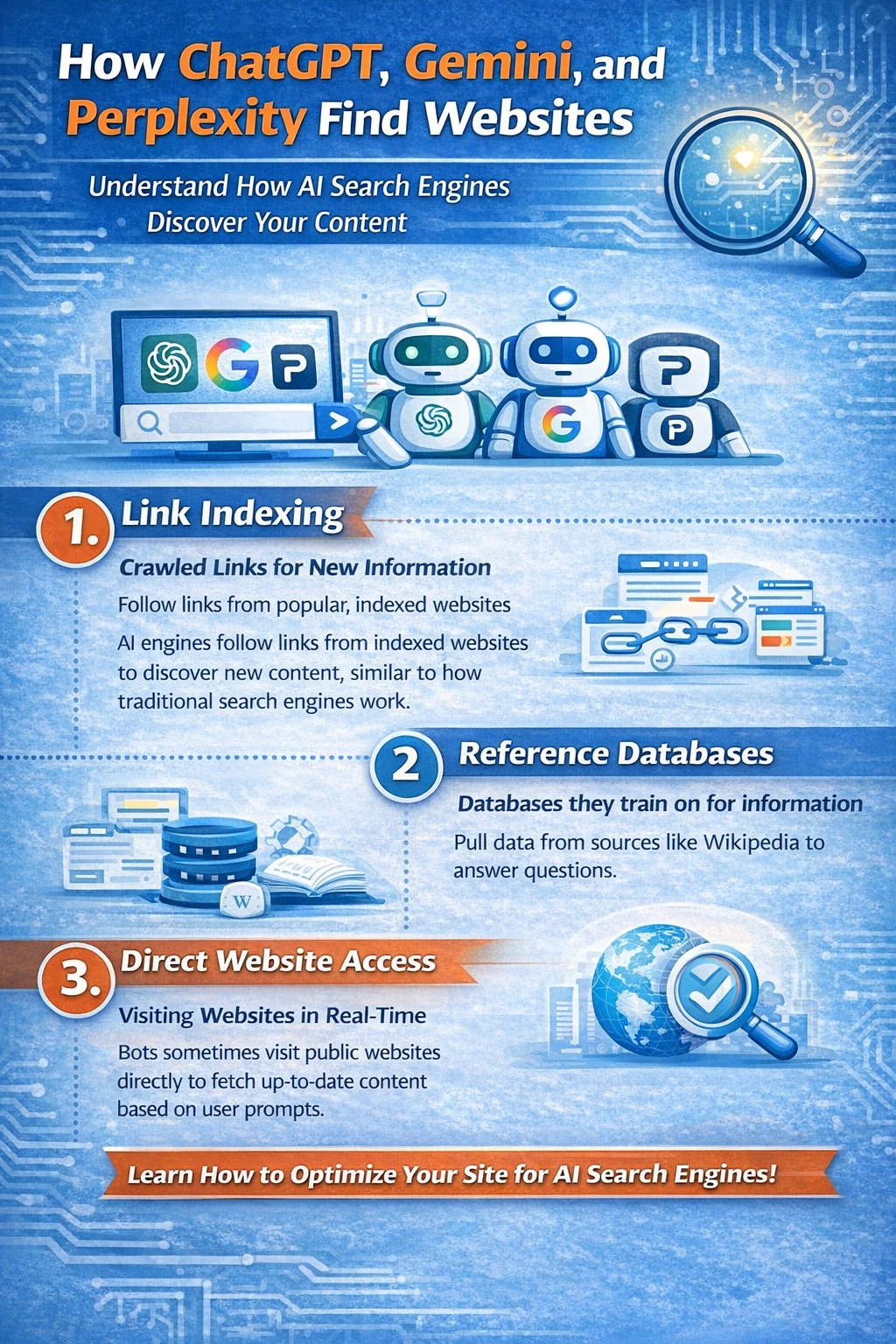
AI-zoeksystemen surfen niet op het internet zoals mensen dat doen.
Ze maken gebruik van een gelaagd ontdekkingssysteem dat is opgebouwd uit zoekindexen, crawlers en ophaalprocessen.
Inzicht in dit systeem is essentieel voor LLM SEO.
De drie belangrijkste manieren waarop LLM-studenten inhoud ontdekken
Moderne AI-zoekmachines gebruiken drie primaire bronnen:
- Traditionele zoekmachine-indexen
- AI-specifieke crawlers
- Gelicentieerde en partnergegevensbronnen
Ieder speelt een andere rol.
1. Zoekmachine-indexen (de primaire bron)
De meeste AI-systemen onderhouden geen eigen, complete webindex.
In plaats daarvan maken ze gebruik van bestaande zoekmachines.
In praktijk:
- ChatGPT (met browsefunctie) gebruikt de Bing-index
- Copilot wordt volledig mogelijk gemaakt door Bing.
- verwarring maakt gebruik van Bing, een eigen crawler en partnerindexen.
- Google Gemini / SGE maakt gebruik van de hoofdindex van Google
Dit betekent iets belangrijks:
Als uw website niet door Google of Bing is geïndexeerd, verschijnt deze niet in de AI-zoekresultaten.
Klassieke SEO vormt nog steeds de basis.
Als uw pagina's geblokkeerd zijn, slecht worden gecrawld of niet worden geïndexeerd, kan LLM SEO niet werken.
2. AI-crawlers en ophaalbots
Naast zoekindexen maken veel AI-platformen ook gebruik van hun eigen crawlers.
Bekende voorbeelden zijn:
- GPTBot (OpenAI)
- VerwarringBot
- ClaudeBot
- AppleBot
Deze rupsen verzamelen:
- Frisse inhoud
- Gestructureerde data
- Bronnen met hoge autoriteit
- Pagina's die regelmatig worden bijgewerkt
In tegenstelling tot Googlebot zijn deze crawlers selectief.
Zij richten zich op:
- Vertrouwde domeinen
- Technische documentatie
- Nieuws- en onderzoekssites
- Goed gestructureerde inhoud
Hier wordt machineleesbaarheid cruciaal.
Pagina's die zijn:
- Langzaam
- Slecht gestructureerd
- Vol met advertenties of scripts
Worden vaak overgeslagen of genegeerd.
3. Gelicentieerde uitgevers en datapartnerschappen
Grote AI-platformen zijn ook afhankelijk van gelicentieerde data.
Dit bevat:
- Nieuwsuitgevers
- Educatieve databases
- Documentatieleveranciers
- Eigen kennisbronnen
Deze bronnen wegen zwaar mee.
Ze bieden:
- Signalen met een hoge mate van vertrouwen
- Nieuwe informatie
- Bevestigde feiten
Dit is een van de redenen waarom gezaghebbende websites veel vaker worden aangehaald in antwoorden van AI.
Hoe het ophalen van informatie daadwerkelijk werkt (achter de schermen)
Wanneer een gebruiker een vraag stelt, doorzoekt het systeem niet het hele internet.
In plaats daarvan voert het een zoekopdracht uit op basis van een beperkte index.
Dit proces verloopt doorgaans in deze volgorde:
- Interpreteer de bedoeling van de vraag.
- Genereer meerdere zoekopdrachten.
- Selecteer de documenten van de beste kandidaten.
- Filteren op autoriteit en actualiteit
- Rangschik passages, niet alleen pagina's.
Slechts een klein aantal documenten overleeft dit proces.
In veel systemen zijn er minder dan 20 pagina's beïnvloedt het uiteindelijke antwoord.
En vaak minder dan 5 bronnen worden daadwerkelijk gebruikt.
Wat bepaalt of uw site in aanmerking komt?
In de ontdekkingsfase evalueren LLM's het volgende:
- Indexdekking (zichtbaarheid in Google/Bing)
- Crawl-toegankelijkheid (robots, prestaties, rendering)
- Domeinvertrouwen en -geschiedenis
- Actuele relevantie
- Versheidssignalen
Dit verklaart een belangrijke regel van LLM SEO:
Als uw website nog niet door zoekmachines als betrouwbaar wordt beschouwd, zullen LLM's deze nooit vinden.
LLM SEO vervangt geen technische SEO.
Het versterkt het.
Versheid versus trainingsgegevens
Een van de grootste misvattingen over LLM's is dat ze alleen gebruikmaken van oude trainingsdata.
In werkelijkheid:
- Trainingsgegevens leveren algemene kennis op.
- Live-opvraging biedt actuele informatie.
Voor de meeste feitelijke en SEO-gerelateerde zoekopdrachten gebruiken moderne AI-systemen:
- Geef de voorkeur aan opgehaalde documenten.
- Sterk nadruk op recente inhoud
- Downgrade verouderde bronnen
Dit betekent:
- Regelmatige updates zijn belangrijk.
- Tijdstempels zijn belangrijk.
- Evergreen-pagina's moeten worden vernieuwd.
Nieuw gezag verslaat oud gezag.
Waarom dit je SEO-strategie verandert
Bij traditionele SEO is een positie op de eerste pagina voldoende.
Bij LLM SEO is ranking slechts het eerste filter.
Na het behalen van een goede ranking moet uw pagina ook aan de volgende eisen voldoen:
- Worden opgehaald
- Wees vertrouwd
- Bevat extracteerbare passages
- Betere prestaties leveren dan concurrerende bronnen
Dit is de reden waarom veel hooggeplaatste pagina's niet in de AI-antwoorden verschijnen.
En waarom sommige pagina's met een lagere ranking vaak worden geciteerd.
De selectiecriteria zijn verschillend.
Waarop LLM-studenten letten bij het kiezen van bronnen
Wanneer een AI-systeem een antwoord genereert, selecteert het geen bronnen willekeurig.
Elke bronvermelding is het resultaat van een rangschikkingsproces dat is ontworpen om de meest betrouwbare en nuttige informatie voor een specifieke vraag te identificeren.
Het begrijpen van dit proces vormt de kern van LLM SEO.
In grote lijnen beoordelen LLM's drie dingen: relevantie, betrouwbaarheid en bruikbaarheid.
Relevantie bepaalt of uw inhoud aansluit bij de bedoeling van de vraag.
Vertrouwen bepaalt of uw website als voldoende gezaghebbend wordt beschouwd om te citeren.
Gebruiksvriendelijkheid bepaalt of het systeem uw content gemakkelijk kan extraheren en hergebruiken.
Alle drie moeten aanwezig zijn.
Relevantie van het onderwerp en afstemming van zoekopdrachten
Het eerste filter is relevantie.
Wanneer een gebruiker een vraag stelt, zoekt het zoeksysteem naar documenten die direct betrekking hebben op dat onderwerp.
Dit proces is niet gebaseerd op exacte trefwoorden.
Het is gebaseerd op semantische gelijkenis.
Het systeem analyseert de betekenis van de zoekopdracht, breidt deze uit naar verwante concepten en haalt vervolgens documenten op die deze concepten diepgaand behandelen.
Pagina's die een onderwerp duidelijk definiëren, gerelateerde subonderwerpen uitleggen en consistente terminologie gebruiken, hebben de voorkeur.
Oppervlakkige pagina's die het onderwerp slechts kort behandelen, worden meestal al vroeg gefilterd.
Daarom is thematische diepgang belangrijker dan zoekwoorddichtheid bij LLM SEO.
Het doel is niet om een zin te evenaren.
Het doel is aan te tonen dat uw pagina over het onderwerp gaat.
Autoriteits- en vertrouwenssignalen
Zodra relevantie is vastgesteld, wordt vertrouwen de belangrijkste factor.
LLM-studenten geven sterk de voorkeur aan bronnen die online als gezaghebbend worden beschouwd.
Autoriteit wordt afgeleid uit vele signalen.
Zoekmachines kijken naar backlink profielen, historische prestaties en domeinstabiliteit.
AI-systemen voegen extra lagen toe.
Ze beoordelen hoe vaak uw merk of domein wordt genoemd in gerenommeerde publicaties.
Ze analyseren of uw content door andere gezaghebbende bronnen wordt geciteerd.
Ze onderzoeken of uw website is gekoppeld aan erkende entiteiten zoals bedrijven, auteurs of instellingen.
In veel gevallen zal een website met een gemiddelde ranking maar een sterke merkbekendheid de voorkeur krijgen boven een hoger gerankte pagina van een onbekend domein.
Vertrouwen is geen eendimensionale maatstaf.
Het is een opgebouwde reputatie.
Entiteitsherkenning en afstemming van kennisgrafieken
Moderne LLM-opleidingen beschouwen websites niet als op zichzelf staande pagina's.
Ze behandelen ze als entiteiten.
Een entiteit kan een merk, een bedrijf, een auteur, een product of een concept zijn.
Als uw website consequent aan een specifiek onderwerp wordt gekoppeld, leert het systeem die relatie kennen.
Dit gebeurt via gestructureerde data, auteursprofielen, Wikipedia-artikelen, bedrijfsdeskundigen vermeldingen en herhaalde berichten op het internet.
Zodra een entiteit is vastgesteld, begint het model deze te bevoordelen wanneer er vragen over dat onderwerp opduiken.
Dit is een van de redenen waarom gevestigde merken de AI-citaten domineren.
Het zijn niet zomaar pagina's die hoog scoren in de zoekresultaten.
Het zijn erkende entiteiten.
Inhoudelijke duidelijkheid en extracteerbaarheid
Zelfs als je pagina relevant en betrouwbaar is, kan deze nog steeds worden afgewezen.
De laatste test is de gebruiksvriendelijkheid.
LLM's lezen teksten niet op dezelfde manier als mensen.
Ze zoeken naar doorgangen die veilig kunnen worden ontgonnen en hergebruikt.
Duidelijke definities, beknopte uitleg en logisch gestructureerde secties presteren het best.
Lange alinea's met opvulling, marketing Tekstuele of dubbelzinnige formuleringen presteren slecht.
AI-systemen geven de voorkeur aan content die feiten direct weergeeft.
Ze geven de voorkeur aan pagina's die vragen beantwoorden in de eerste paar zinnen van een onderdeel.
Ze geven de voorkeur aan schrijfstijlen die metaforen, overdrijvingen en onnodige complexiteit vermijden.
Hoe makkelijker je content te begrijpen is, hoe groter de kans dat deze geciteerd wordt.
Versheid en tijdsignalen
Bij veel zoekopdrachten speelt actualiteit een doorslaggevende rol.
AI-systemen downgraden bronnen die verouderd lijken.
Ze kijken naar publicatiedata, updategeschiedenis, interne links en externe referenties.
Als twee pagina's even gezaghebbend zijn, wint de meest recente pagina meestal.
Dit geldt met name voor onderwerpen die te maken hebben met technologie, SEO en AI.
Regelmatige updates geven aan dat uw site actief wordt onderhouden.
Dat alleen al kan de frequentie van citaties verhogen.
Waarom sommige locaties steeds opnieuw worden gekozen
Na verloop van tijd ontwikkelen LLM-studenten voorkeuren.
Wanneer een bron consequent accurate en goed gestructureerde antwoorden levert, leert het systeem die bron te vertrouwen.
Die sites blijven steeds terugkomen in gerelateerde zoekopdrachten.
Dit creëert een feedbacklus.
Meer verwijzingen leiden tot strengere signalen ten aanzien van de entiteit.
Sterkere entiteitssignalen leiden tot meer citaties.
Zo ontstaat autoriteit in AI-zoekopdrachten.
SEO-rankingfactoren voor LLM
LLM SEO is niet afhankelijk van één enkel rankingcriterium.
Het is het resultaat van meerdere systemen die samenwerken om te bepalen of een pagina betrouwbaar genoeg is om een door AI gegenereerd antwoord te beïnvloeden.
Sommige van deze signalen zijn afkomstig van traditionele SEO.
Andere zijn specifiek voor ophaal- en taalmodellen.
Samen vormen ze het rangschikkingskader achter AI-zoekopdrachten.
Actuele autoriteit
Actuele expertise is het sterkste signaal in LLM SEO.
AI-systemen geven sterk de voorkeur aan websites die blijk geven van aanhoudende expertise op een specifiek vakgebied.
Dit wordt niet gemeten aan de hand van één enkele pagina.
Het wordt gemeten over uw gehele domein.
Wanneer uw website meerdere kwalitatief hoogwaardige artikelen over hetzelfde onderwerp publiceert, leert het systeem dat uw merk een betrouwbare bron is voor dat onderwerp.
Dit is waarom contentclusters zo belangrijk zijn.
Een losstaand artikel over LLM SEO wordt zelden geciteerd.
Een website met twintig gerelateerde artikelen wordt een standaardbron.
Autoriteit wordt opgebouwd door breedvoerigheid, consistentie en diepgang.
Domeinvertrouwen en historische signalen
Vertrouwen op domeinniveau speelt nog steeds een belangrijke rol.
LLM-systemen ontlenen een groot deel van hun vertrouwensstructuur aan zoekmachines.
Ze beoordelen hoe lang een domein al bestaat, hoe stabiel het is en hoe het in het verleden heeft gepresteerd.
Websites met een lange publicatiegeschiedenis, een schoon backlinkprofiel en consistente indexering hebben de voorkeur.
Spamsignalen, inhoud van lage kwaliteit en frequente eigendomswisselingen ondermijnen het vertrouwen.
Dit verklaart waarom nieuwe domeinen moeite hebben om in AI-antwoorden te verschijnen, zelfs als hun content sterk is.
Vertrouwen groeit langzaam.
Maar eenmaal gevestigd, wordt het een groot voordeel.
Merkvermeldingen en reputatiesignalen
In LLM SEO zijn vermeldingen vaak net zo belangrijk als links.
AI-systemen beoordelen hoe vaak een merk of website wordt genoemd in gezaghebbende publicaties.
Ze zoeken naar terugkerende verbanden tussen uw merk en specifieke onderwerpen.
Ze onderzoeken of journalisten, onderzoekers en brancheblogs naar uw werk verwijzen.
Deze vermeldingen worden direct gebruikt voor entiteitsherkenning.
Een merk dat vaak in vertrouwde contexten verschijnt, heeft een grotere kans om als bron te worden gekozen, zelfs als de pagina niet bovenaan de Google-zoekresultaten staat.
Dit is een van de belangrijkste redenen waarom digitale PR een essentieel onderdeel wordt van AI-zoekmachineoptimalisatie.
Inhoudsstructuur en machineleesbaarheid
Zodra de autoriteit is gevestigd, wordt de kwaliteit van de inhoud doorslaggevend.
LLM-studenten geven de voorkeur aan pagina's die gemakkelijk te interpreteren zijn.
Expliciete kopjes, een logische structuur van de secties en expliciete definities vergroten de extracteerbaarheid.
Pagina's die een concept op een gestructureerde manier uitleggen, presteren doorgaans beter dan pagina's die daarop vertrouwen. Verhalen vertellen of marketingtaal gebruiken.
De eerste zinnen van een paragraaf zijn bijzonder belangrijk.
Ze worden vaak gebruikt als samenvattende kandidaten.
Als uw pagina de vraag niet meteen duidelijk beantwoordt, is de kans klein dat deze wordt geciteerd.
In LLM SEO is opmaak geen cosmetisch aspect.
Het is een rankingfactor.
Gestructureerde data en semantische opmaak
Gestructureerde data biedt context die onopgemaakte tekst niet kan bieden.
Schema-opmaak helpt AI-systemen te begrijpen wat een pagina voorstelt, wie hem heeft geschreven, waar hij over gaat en hoe verschillende entiteiten met elkaar verband houden.
Artikelstructuur, FAQ-structuur, organisatiestructuur en persoonsstructuur zijn bijzonder invloedrijk.
Hoewel een schema op zich geen garantie is voor bronvermelding, verbetert het de begrijpelijkheid aanzienlijk.
Bij concurrerende zoekopdrachten presteren gestructureerde pagina's doorgaans beter dan ongestructureerde pagina's.
Schema fungeert als een vertaallaag tussen uw content en de machine.
Backlinks en citatiegrafieken
Backlinks blijven belangrijk.
Maar hun rol verandert.
In LLM SEO zijn links niet alleen autoriteitssignalen.
Ze maken ook deel uit van een citatiegrafiek.
AI-systemen onderzoeken welke bronnen naar elkaar verwijzen en hoe informatie zich over het web verspreidt.
Pagina's die vaak worden geciteerd door gezaghebbende websites, worden vaker geraadpleegd en als betrouwbaar beschouwd.
In veel gevallen heeft een kleiner aantal hoogwaardige redactionele links meer impact dan een groot aantal laagwaardige backlinks.
Kwaliteit weegt meer dan ooit zwaarder dan kwantiteit.
Versheids- en updatesignalen
Versheid speelt een belangrijkere rol in AI-zoekopdrachten zijn effectiever dan klassieke SEO.
Bij LLM-opleidingen ligt de nadruk sterk op recente inhoud voor technische en snel veranderende onderwerpen.
Ze evalueren publicatiedata, updatefrequentie, interne revisiesignalen en externe referenties.
Een goed onderhouden pagina die om de paar maanden wordt bijgewerkt, presteert vaak beter dan een ouder, gezaghebbend artikel dat al jaren niet is aangepast.
Vernieuwing betekent niet dat je alles opnieuw moet schrijven.
Het gaat erom aan te geven dat uw informatie nog steeds geldig is.
Signalen van betrokkenheid en gebruik
Sommige AI-systemen bevatten indirecte interactiegegevens.
Dit omvat onder meer hoe vaak een bron wordt geselecteerd, hoe lang gebruikers interactie hebben met antwoorden die ernaar verwijzen, en of vervolgvragen dezelfde bron aanhalen.
Hoewel deze signalen niet volledig transparant zijn, creëren ze een feedbacklus.
Bronnen die goed presteren, blijven geselecteerd worden.
Bronnen die gebrekkige antwoorden opleveren, verdwijnen geleidelijk.
Prestaties versterken het gezag.
De SEO-ranking van LLM wordt niet door één trucje bepaald.
Het is het gecombineerde resultaat van gezag, vertrouwen, structuur en duidelijkheid.
Als alle vier op één lijn liggen, worden citaties voorspelbaar.
Hoe maximaliseer je content voor LLM SEO?
Optimaliseren voor LLM SEO betekent niet dat je alles opnieuw moet schrijven.
Het gaat erom de manier waarop informatie wordt gepresenteerd te veranderen, zodat AI-systemen deze gemakkelijk kunnen ophalen, begrijpen en hergebruiken.
Het doel is simpel: zorg ervoor dat jouw content de gemakkelijkste en veiligste bron is voor een AI om te citeren.
Schrijf in een antwoordgerichte volgorde.
LLM-studenten geven de voorkeur aan inhoud die direct antwoord geeft op vragen.
Aan het begin van een sectie moet de eerste zin het concept definiëren of de vraag direct beantwoorden.
Dit lijkt op de manier waarop zoeksystemen passages extraheren.
Pagina's die het antwoord vertragen met inleidingen, anekdotes of marketingtaal worden vaak overgeslagen.
De meest geciteerde pagina's plaatsen hun definitie of conclusie meestal in de eerste twee regels van een sectie.
Dit is niet voor lezers.
Het is voor machines.
Gebruik relevante trefwoorden die aansluiten bij de zoekintentie.
Kopteksten fungeren als ankers voor het ophalen van informatie.
Wanneer een AI een document scant, kijkt het naar de koppen om te begrijpen wat elke sectie bevat.
Kopteksten die aansluiten op echte gebruikersvragen presteren het beste.
In plaats van vage titels werkt een precieze formulering beter.
Een kop als "Hoe LLM's bronnen selecteren" is veel effectiever dan "Onze aanpak van AI-gestuurd zoeken".
Door zoekopdrachten in natuurlijke taal te matchen, vergroot je de kans dat je sectie wordt opgehaald met de juiste intentie.
Structuur van de inhoud voor extractie, niet voor overtuiging.
Traditionele SEO legt doorgaans de nadruk op storytelling en overtuiging.
LLM SEO geeft prioriteit aan extracteerbaarheid.
Goed presterende pagina's zijn logisch ingedeeld, gebruiken korte alinea's en vermijden complexiteit.
Elke sectie moet één idee volledig uitleggen voordat naar de volgende wordt overgegaan.
Lange alinea's met meerdere onderwerpen zijn moeilijk te verwerken voor zoeksystemen.
Duidelijke onderwerpgrenzen maken het voor het model gemakkelijker om bruikbare passages te selecteren.
Gebruik definities, samenvattingen en expliciete verklaringen.
LLM-opleidingen zijn conservatief.
Ze geven de voorkeur aan bronnen die de feiten helder weergeven.
Definities, uitleg en samenvattingen zijn bijzonder waardevol omdat ze veilig hergebruikt kunnen worden.
Pagina's die zich inhouden, overmatig speculeren of zich baseren op meningen, worden minder vaak geciteerd.
Hoe directer je uitspraken zijn, hoe vaker je ze kunt gebruiken.
Dit is de reden waarom handleidingen, documentatie en naslagwerken de boventoon voeren in AI-citaten.
Versterk de betekenis met behulp van de interne context.
AI-systemen lezen een individuele zin niet geïsoleerd.
Ze beoordelen de omringende context.
Wanneer je een concept introduceert, versterk het dan door op de hele pagina consistente terminologie te gebruiken.
Vermijd het wisselen tussen verschillende benamingen voor hetzelfde idee.
Semantische consistentie verbetert de effectiviteit van zoekopdrachten en vermindert ambiguïteit.
Dit is met name belangrijk voor nieuwe concepten zoals LLM SEO, waar de definities nog steeds in ontwikkeling zijn.
Optimaliseer voor entiteiten, niet alleen voor zoekwoorden.
LLM SEO is in de eerste plaats entiteitsgericht.
Wanneer je belangrijke concepten, merken, tools of personen noemt, leg dan duidelijk het verband met hun rol.
Leg uit wat ze zijn en hoe ze verband houden met het onderwerp.
Dit versterkt de entiteitsherkenning en helpt het systeem een kennisgrafiek rondom uw content op te bouwen.
Pagina's die sterke verbanden tussen entiteiten leggen, worden veel vaker geciteerd.
Handhaaf een hoge feitelijke dichtheid.
AI-systemen geven de voorkeur aan pagina's met een hoge informatie-woordverhouding.
Overbodige formuleringen, stopwoordjes en marketingtaal verkleinen de kans op citaties.
De meest geciteerde pagina's bevatten een schat aan uitleg, definities en nuttige inzichten.
Dit betekent niet dat je saaie teksten moet schrijven.
Dat betekent dat elke zin betekenis moet toevoegen.
Ontwerp voor hergebruik in meerdere zoekopdrachten
Sterke SEO-content voor LLM-opleidingen is modulair opgebouwd.
De afzonderlijke onderdelen kunnen op zichzelf staan en antwoord geven op verschillende vragen.
Wanneer een pagina meerdere gerelateerde subonderwerpen in duidelijk gescheiden secties behandelt, komt deze in aanmerking voor veel verschillende zoekopdrachten.
Dit is een van de redenen waarom pijlerpagina's zo goed presteren in AI-zoekopdrachten.
Ze fungeren als een bibliotheek met antwoorden binnen één enkele URL.
Werk de inhoud bij naarmate modellen en systemen veranderen.
LLM SEO is zeer gevoelig voor actualiteit.
Naarmate modellen verbeteren, veranderen de rangschikkingscriteria.
Pagina's die regelmatig worden gecontroleerd en bijgewerkt, blijven zichtbaar.
Dit hoeft niet vaak herschreven te worden.
Vaak zijn kleine wijzigingen, zoals het toevoegen van een nieuwe sectie, het vernieuwen van voorbeelden of het bijwerken van datums, al voldoende om de relevantie aan te tonen.
Verouderde pagina's verdwijnen geleidelijk uit de antwoorden van de AI.
Onderhouden pagina's samengestelde autoriteit.
Optimaliseren voor LLM SEO draait niet om het manipuleren van algoritmes.
Het gaat erom content te publiceren die algoritmes kunnen vertrouwen.
Als uw pagina's duidelijk, gezaghebbend, gestructureerd en actueel zijn, wordt de selectie voorspelbaar.
Schema-opmaak en gestructureerde data voor AI-zoekopdrachten
Gestructureerde data speelt een cruciale rol in LLM SEO.
Hoewel grote taalmodellen eenvoudige tekst kunnen lezen, zijn ze sterk afhankelijk van gestructureerde signalen om te begrijpen wat een pagina voorstelt, wie deze heeft gemaakt en hoe verschillende concepten met elkaar verband houden.
Schema-opmaak fungeert als een vertaallaag tussen menselijke taal en machine-interpretatie.
Het vermindert de onduidelijkheid.
En bij AI-zoekopdrachten is dubbelzinnigheid de vijand.
Waarom gestructureerde data belangrijker is bij AI-zoekopdrachten
Traditionele zoekmachines gebruiken schema's voornamelijk voor uitgebreide resultaten en verbeterde tekstfragmenten.
AI-systemen gebruiken het op een andere manier.
Ze gebruiken gestructureerde data om entiteitsgrafieken op te bouwen, feiten te valideren en betekenis toe te kennen aan content.
Wanneer een LLM een document ophaalt, leest het niet alleen de zichtbare tekst.
Het leest ook metadata.
Informatie over de auteur, gegevens over de organisatie, publicatiedata en het type inhoud hebben allemaal invloed op hoe betrouwbaar en herbruikbaar een bron lijkt.
Pagina's met overzichtelijke, consistente en gestructureerde gegevens zijn gemakkelijker te classificeren.
Dit alleen al verhoogt hun kans om geselecteerd te worden.
Schema als entiteitssignaal
LLM SEO is sterk entiteitsgericht.
Gestructureerde data helpt om die entiteiten expliciet te definiëren.
Wanneer je je organisatie, je auteurs, je producten of je artikelen van een markering voorziet, vertel je machines precies wie je bent en waar je voor staat.
Dit is belangrijk omdat AI-systemen afhankelijk zijn van entiteitsrelaties om autoriteit te bepalen.
Als uw website duidelijk is gekoppeld aan een erkende organisatie of een deskundige auteur, wint deze aan geloofwaardigheid.
Als uw pagina's geen identificatiekenmerken bevatten, blijven ze anoniem.
Anonieme pagina's worden zelden geciteerd.
Hoe schema's het succes van zoekresultaten verbeteren
Zoeksystemen filteren documenten regelmatig voordat ze worden gerangschikt.
Gestructureerde data zorgt ervoor dat je pagina de filter doorstaat.
Het artikelschema verduidelijkt dat een pagina een redactionele bron is.
Het FAQ-schema benadrukt vraag-en-antwoordpatronen.
Organisatie- en Persoonsschema's koppelen inhoud aan daadwerkelijke entiteiten.
Deze signalen verminderen de kans op verkeerde classificatie.
Ze helpen ook zoeksystemen om uw pagina te koppelen aan het juiste zoektype.
Een pagina die duidelijk is gemarkeerd als handleiding, definitie of naslagwerk, wordt eerder geraadpleegd voor informatieve vragen.
Gestructureerde data en vertrouwensvalidatie
AI-systemen zijn per definitie conservatief.
Ze vermijden het citeren van bronnen die dubbelzinnig of onbetrouwbaar lijken.
Gestructureerde data levert verificatiesignalen op.
De publicatiedatum bevestigt de versheid.
De velden met auteursgegevens bevestigen de verantwoordelijkheid.
Organisatiemarkering bevestigt eigendom.
In veel systemen worden deze velden vergeleken met externe kennisgrafieken.
Als ze het met elkaar eens zijn, neemt het vertrouwen toe.
Als er conflicten zijn of als de gegevens ontbreken, kan de pagina een lagere beoordeling krijgen of genegeerd worden.
Dit is een van de redenen waarom anonieme content slecht presteert in AI-zoekopdrachten.
De rol van FAQ- en HowTo-schema's in LLM SEO
De FAQ- en HowTo-schema's spelen een speciale rol in LLM SEO.
Ze koppelen vragen expliciet aan antwoorden.
Dit formaat weerspiegelt de interne werking van AI-zoekopdrachten.
Secties die zijn gemarkeerd met het FAQ-schema worden vaak direct opgenomen in AI-antwoorden.
Niet omdat het schema zelf gerangschikt is, maar omdat het perfect gestructureerde antwoordeenheden creëert.
Goed geschreven FAQ-secties komen vaak in aanmerking voor citatie.
Dit is met name effectief voor technische en educatieve onderwerpen.
Gestructureerde data is geen snelkoppeling.
Het schema heft de autoriteit niet op.
Een zwakke website met perfecte markup zal niet beter presteren dan een betrouwbare website zonder markup.
Maar wanneer twee gezaghebbende pagina's met elkaar concurreren, worden gestructureerde gegevens vaak de doorslaggevende factor.
Het bevordert het begrip.
Het vergroot het zelfvertrouwen.
En het verbetert de extractie.
Bij concurrerende AI-zoekopdrachten tellen die kleine voordelen op.
De langetermijnwaarde van gestructureerde data
Het schema biedt ook voordelen op de lange termijn.
Het voedt kennisgrafieken.
Na verloop van tijd worden uw organisatie, auteurs en onderwerpen onderdeel van het machinegeheugen.
Zodra dat gebeurt, verschijnt uw website vaker in de zoekresultaten voor gerelateerde zoekopdrachten.
Zo worden merken de standaardbron in AI-zoekopdrachten.
Niet via één enkel artikel.
Door middel van consistente identiteitssignalen over het gehele domein.
Gestructureerde data garandeert geen bronvermelding.
Maar zonder dat wordt het veel moeilijker om consistent zichtbaar te blijven in AI-zoekresultaten.
Wat is llm.txt en is het belangrijk voor LLM SEO?

Naarmate AI-crawlers gangbaarder werden, begon er een nieuw type bestand op websites te verschijnen.
Het heet llm.txt.
Het is specifiek ontworpen voor grote taalmodellen.
Wat is llm.txt?
llm.txt is een voorgestelde standaard waarmee website-eigenaren kunnen bepalen hoe AI-systemen toegang krijgen tot hun content en deze gebruiken.
Het werkt vergelijkbaar met robots.txt.
Maar in plaats van zoekmachinecrawlers te beheren, beheert het... AI-modelcrawlers en trainingspipelines.
Met llm.txt kunnen uitgevers het volgende verklaren:
- Of AI-bots de site mogen crawlen.
- Welke secties zijn wel of niet toegestaan?
- Of de inhoud geschikt is voor trainingsdoeleinden.
- Of de inhoud gebruikt kan worden voor het opzoeken en beantwoorden van vragen.
Het bestand bevindt zich in de rootmap van een domein.
Wanneer een AI-crawler een site bezoekt, controleert deze eerst het bestand llm.txt voordat de inhoud wordt verzameld.
Waarom llm.txt bestaat
Het traditionele robots.txt-bestand was ontworpen voor zoekmachine-indexering.
Het was nooit ontworpen om AI-training of hergebruik van content te beheren.
Naarmate grote taalmodellen steeds grotere delen van het web begonnen te scrapen, uitten uitgevers hun bezorgdheid over:
- Ongeautoriseerde training over gelicentieerde inhoud
- Gebruik van data waarvoor betaald moet worden of die eigendom is van de verzekeraar.
- Gebrek aan erkenning en compensatie
llm.txt verscheen als antwoord.
Het doel is om uitgevers een manier te bieden om toestemming te geven en controle uit te oefenen.
Geen voorkeuren rangschikken.
Toegangsrechten.
Heeft llm.txt invloed op rankings of citaties?
Op dit moment verbetert llm.txt de rankings niet direct.
Het is geen rankingfactor.
En het biedt geen garantie voor zichtbaarheid.
De meeste grote AI-platformen vertrouwen nog steeds voornamelijk op zoekindexen in plaats van op directe crawling.
Dat betekent dat het blokkeren of toestaan van llm.txt meestal geen invloed heeft op de vraag of uw content wordt weergegeven in Google SGE, ChatGPT of Perplexity.
Llm.txt kan echter toekomstige wijzigingen aanbrengen. gegevenspijplijnen.
Sommige AI-crawlers respecteren dit al.
Anderen beginnen er ook mee te experimenteren.
Na verloop van tijd kan het de standaard besturingslaag worden voor:
- Trainingsgegevensverzameling
- Ophaalpijplijnen
- Beleid voor hergebruik van content
Dat maakt het strategisch belangrijk, zelfs als de SEO-impact op korte termijn beperkt is.
Wanneer llm.txt van belang is voor LLM SEO
llm.txt wordt in drie situaties relevant.
Ten eerste, wanneer je wilt blok AI-training maar zoekindexering blijft wel mogelijk.
Ten tweede, wanneer je het ophalen en citeren van informatie wilt toestaan, maar de modeltraining wilt beperken.
Ten derde, wanneer u een website met premium content of eigen content beheert, heeft u juridische controle nodig.
Voor de meeste informatieve websites is llm.txt niet nodig voor de zichtbaarheid.
Maar het is wel nuttig voor het bestuur.
Het laat AI-systemen weten dat uw site de regels voor AI-toegang begrijpt.
Dat alleen al kan het vertrouwen in de loop der tijd versterken.
llm.txt versus robots.txt
robots.txt regelt het crawlen door zoekmachines.
llm.txt regelt het crawlen en het gebruik ervan door AI-systemen.
robots.txt beantwoordt de vraag:
“Kunt u deze pagina indexeren?”
llm.txt beantwoordt een andere vraag:
“Kun je deze inhoud gebruiken om systemen te trainen of antwoorden te genereren?”
Ze lossen verschillende problemen op.
Ze vullen elkaar aan, ze vervangen elkaar niet.
De strategische rol van llm.txt
Hoewel llm.txt nog steeds in ontwikkeling is, is de rol ervan op de lange termijn duidelijk.
AI-zoekopdrachten zullen steeds vaker afhankelijk zijn van expliciete toestemming van de uitgever.
Naarmate de regelgeving toeneemt en de licentieverlening zich uitbreidt, zullen platforms de voorkeur geven aan content die:
- Duidelijk gelicentieerd
- Uitdrukkelijk toegestaan
- Juridisch veilig
In die toekomst zou llm.txt een vertrouwenssignaal kunnen worden.
Niet voor ranking.
Maar wel voor de toelatingseisen.
Websites die AI volledig blokkeren, verdwijnen mogelijk uit de AI-antwoorden.
Websites met gecontroleerde toegang kunnen de voorkeursbronnen worden.
Moet je llm.txt vandaag nog toevoegen?
Voor de meeste SEO-gerichte websites is llm.txt optioneel.
Het zal de verkeersdrukte niet verhogen.
Het zal de ranking niet verbeteren.
Maar het maakt je website wel toekomstbestendig.
Het duidt op bewustzijn.
En het geeft je controle.
Voor uitgevers, bureaus en merken die actief zijn in sectoren waar AI een belangrijke rol speelt, is dat op zich al waardevol.
llm.txt is geen magische SEO-tool.
Maar het is wel een van de eerste bouwstenen van het uitgeven in het AI-tijdperk.
Lees meer over: Mijn linkbuildingplan: hoe ik links bouw die Google vertrouwt.
Hoe merkvermeldingen en entiteiten de SEO van LLM beïnvloeden
LLM SEO is gebouwd rond entiteiten, niet rond individuele pagina's.
Moderne AI-systemen behandelen elke URL niet als een op zichzelf staand document. Ze proberen te achterhalen wie er achter de content zit, waar de bron bekend om staat en of deze een reputatie heeft in de echte wereld. Zodra een website, merk of auteur als een entiteit wordt herkend, wint elk stukje content dat ermee verbonden is aan vertrouwen.
Dit is een van de grootste structurele verschillen tussen klassieke SEO en AI-gestuurd zoeken.
Van pagina's naar identiteiten
Traditionele zoekmachines rangschikken pagina's.
AI-systemen rangschikken identiteiten.
Voordat een LLM de kwaliteit van een specifiek artikel beoordeelt, onderzoekt het eerst de bron van dat artikel. Het zoekt naar signalen die aangeven of de website een bekend merk, een erkende expert of een legitieme organisatie vertegenwoordigt.
Als het systeem zonder zekerheid kan vaststellen wie de eigenaar van de content is of waar de bron voor bekend staat, begint de pagina al met een achterstand. Zelfs goed geschreven artikelen worden vaak genegeerd als de identiteit erachter zwak of onduidelijk is.
Hoe werkt entiteitsherkenning?
AI-platformen onderhouden grote interne kennisgrafieken.
Deze grafieken verbinden merken met sectoren, auteurs met onderwerpen, bedrijven met producten en publicaties met vakgebieden. Deze informatie is afkomstig uit gestructureerde data, auteursprofielen, Wikipedia- en Wikidata-pagina's, bedrijfsvermeldingen, persberichten en herhaalde citaties op het web.
Wanneer deze signalen consistent zijn, leert het systeem dat een specifieke entiteit wordt beschouwd voor een bepaald onderwerp. Zodra die associatie bestaat, wordt toekomstige content van dezelfde entiteit agressiever opgehaald en gerangschikt.
Dit proces vindt continu en automatisch plaats.
Waarom gevestigde merken de AI-antwoorden domineren
Dit is de reden waarom grote merken en bekende uitgevers zo vaak in AI-zoekresultaten verschijnen.
Dat komt niet alleen doordat hun content beter is.
Dat komt doordat hun identiteit al vertrouwd is.
Wanneer een AI-systeem een zoekopdracht verwerkt, begint het vaak met het zoeken naar betrouwbare entiteiten die aan dat onderwerp zijn gekoppeld. Pagina's van die entiteiten worden als eerste opgehaald. Kleinere of onbekende websites komen mogelijk nooit in de kandidatenlijst terecht, zelfs als hun inhoud technisch gezien sterker is.
Vertrouwen fungeert als een filter nog voordat de rangschikking begint.
De rol van merkvermeldingen in LLM SEO
In LLM SEO zijn reputatiesignalen niet beperkt tot backlinks.
AI-systemen registreren hoe vaak een merk of domein wordt genoemd in gezaghebbende bronnen. Deze vermeldingen verschijnen in nieuwsartikelen, onderzoeksrapporten, documentatie, brancheblogs en online discussies.
Zelfs als er geen hyperlink aanwezig is, draagt de vermelding nog steeds bij aan de merkbekendheid. Herhaalde associaties tussen een merk en een onderwerp versterken na verloop van tijd de expertise.
Dit is de reden waarom digitale PR en merkbekendheid nu een directe invloed hebben op AI-rankings.
Vermeldt het geheugen van de build.
Auteursbevoegdheid en persoonlijke entiteiten
Auteurs worden ook als entiteiten beschouwd.
Wanneer een auteur consistent over een bepaald onderwerp publiceert en zijn of haar naam in meerdere betrouwbare bronnen voorkomt, leert het systeem dat de auteur expertise op dat gebied heeft. Artikelen geschreven door erkende auteurs worden vaker opgezocht en geciteerd.
Dit is een van de redenen waarom auteursbiografieën, consistente auteursvermeldingen en openbare profielen nu veel belangrijker zijn dan in de traditionele SEO.
Bij AI-zoekopdrachten is de geloofwaardigheid net zo belangrijk voor de auteur als voor het vakgebied.
Hoe entiteitssignalen het ophalen van informatie beïnvloeden
De sterkte van een entiteit beïnvloedt de ophaalfase, niet alleen de rangschikking.
Bij het verwerken van een zoekopdracht beperken veel systemen de mogelijke documenten tot bronnen die zijn gekoppeld aan vertrouwde entiteiten. Pagina's van onbekende of zwakke entiteiten worden mogelijk nooit opgehaald, ongeacht hoe goed ze zijn geoptimaliseerd.
Dit creëert een stille barrière.
Je pagina kan technisch perfect zijn en toch nooit in de AI-antwoorden verschijnen, omdat je entiteit niet betrouwbaar genoeg wordt geacht om te worden opgenomen.
Autoriteit van de gebouwbeheerder voor langetermijnzichtbaarheid
Autoriteit binnen een organisatie wordt opgebouwd door consistentie.
Het publiceren van meerdere diepgaande artikelen over een specifiek onderwerp.
Het verkrijgen van citaten van gerenommeerde bronnen.
Het is belangrijk om de auteurs- en organisatiegegevens duidelijk bij te houden.
Vermeld worden in gerenommeerde publicaties.
Zodra een entiteit is opgericht, neemt de zichtbaarheid toe.
Nieuwe pagina's scoren sneller in de zoekresultaten.
Het aantal citaties neemt toe.
Het merk wordt een standaardbron voor gerelateerde zoekopdrachten.
In LLM SEO is dit effect sterker dan dat van welke individuele backlink dan ook.
Bij AI-zoekopdrachten behalen pagina's hogere rankings.
Maar entiteiten winnen ophalen.
Als deze toon beter werkt (en dat zou zo moeten zijn), gaan we vervolgens verder met:
Hoe je verkeer en zichtbaarheid kunt volgen via AI-zoekopdrachten
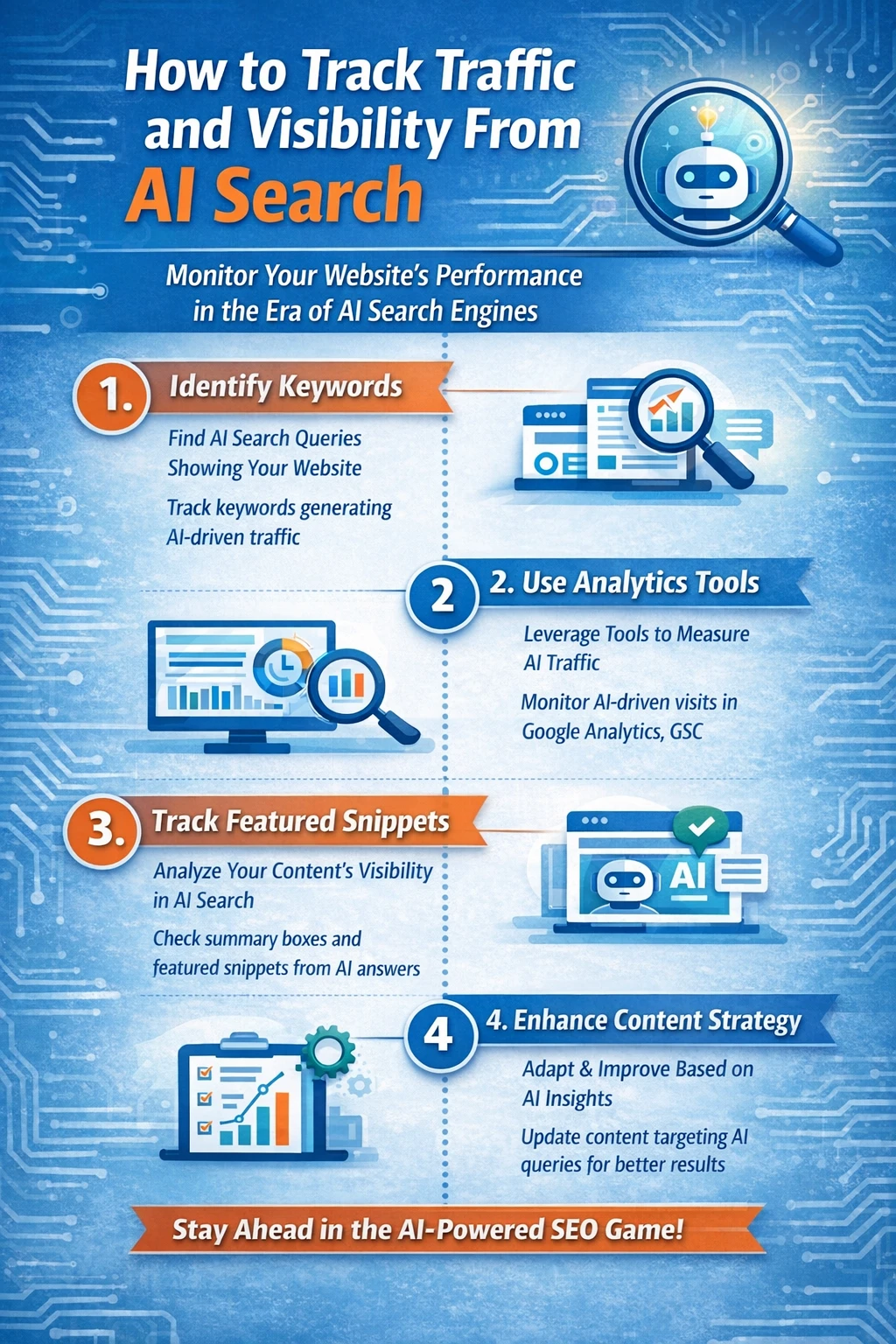
Het bijhouden van verkeer afkomstig van AI-zoekopdrachten is een van de moeilijkste problemen in de moderne SEO.
Niet omdat de data ontbreekt, maar omdat de meeste analysesystemen nooit zijn ontworpen om te meten hoe AI-platforms informatie verspreiden. Traditionele analyses gaan uit van een eenvoudig model: een gebruiker klikt op een link, komt op een website terecht en het bezoek wordt geregistreerd met een verwijzer. AI-zoekmachines doorbreken dit model bijna volledig.
Bij veel AI-toepassingen klikken gebruikers nooit op een bron. Ze lezen het antwoord in ChatGPT, Perplexity of Google SGE en gaan verder. In dat geval kan uw content de gebruiker beïnvloeden, maar zonder dat er een geregistreerde sessie plaatsvindt. Vanuit een analyseperspectief is die invloed onzichtbaar.
Waarom AI-verkeer zelden in analyses verschijnt
De meeste AI-platforms geven geen consistente verwijzingsgegevens door wanneer gebruikers doorklikken naar een bron. Sommige platforms maskeren de verwijzing volledig. Andere platforms leiden verkeer om via interne redirect-systemen die de bronvermelding verwijderen.
Wanneer bezoeken wel in GA4 verschijnen, worden ze vaak verkeerd geclassificeerd. Veel ervan worden weergegeven als direct verkeer. Andere verschijnen als niet-toegewezen sessies of generiek verwijzingsverkeer van onbekende domeinen. Slechts een klein deel van de door AI gegenereerde bezoeken wordt correct gelabeld als afkomstig van een AI-platform.
Dit betekent dat standaard organisch verkeer Rapporten onderschatten de werkelijke impact van AI-zoekmachines aanzienlijk.
In veel gevallen leidt de meeste zichtbaarheid via AI tot geen meetbaar verkeer.
Het verschil tussen verkeer en invloed
In LLM SEO zijn verkeer en invloed niet langer hetzelfde.
Een traditioneel zoekresultaat beïnvloedt een gebruiker pas nadat er op geklikt is. Een antwoord van AI beïnvloedt de gebruiker al vóórdat er geklikt wordt. De gebruiker kan het antwoord vertrouwen, de aanbeveling opvolgen of een beslissing nemen zonder ooit de bron te bezoeken.
Vanuit het oogpunt van branding en autoriteit is deze invloed vaak waardevoller dan een enkel bezoek. Maar vanuit een analytisch perspectief laat het geen spoor achter.
Dit is de reden waarom klassieke SEO-statistieken, zoals sessies, klikken en rankings, niet langer het volledige verhaal vertellen.
Hoe AI-verkeer indirect te detecteren
Hoewel de meeste blootstelling aan AI onzichtbaar is, zijn er toch enkele signalen zichtbaar.
Af en toe scannen diensten zoals Perplexity, Copilot of ChatGPT de headers van doorverwijzingen. Deze bezoeken vertonen meestal een kenmerkend patroon. Ze zijn doorgaans kleinschalig maar van hoge kwaliteit, met langere sessieduur en een lager bouncepercentage.
Na verloop van tijd zult u wellicht merken dat bepaalde domeinen steeds terugkerende kleine hoeveelheden verwijzingsverkeer genereren. Deze domeinen corresponderen vaak met AI-interfaces of browsers die gebruikmaken van AI.
Deze methode meet geen invloed op grote schaal, maar helpt wel te bevestigen dat uw content door AI-systemen wordt gebruikt.
Het meten van AI-zichtbaarheid in plaats van klikken
Omdat verkeersgegevens onbetrouwbaar zijn, richt LLM SEO zich op zichtbaarheid in plaats van op bezoekersaantallen.
De belangrijkste vraag is of uw website wordt geciteerd, waarnaar wordt verwezen of die wordt aangehaald in de door AI gegenereerde antwoorden.
De meest nauwkeurige manier om dit tegenwoordig te meten is handmatig testen. Door regelmatig dezelfde zoekopdrachten uit te voeren in ChatGPT, Perplexity, Copilot en Google SGE, kunt u bijhouden of uw domein als bron wordt weergegeven en hoe vaak het wordt geselecteerd.
Na verloop van tijd ontstaan er patronen. Bepaalde pagina's worden herhaaldelijk geciteerd. Bepaalde zoekopdrachten leveren steevast dezelfde bronnen op. Dit geeft je een praktisch overzicht van je AI-zoekgedrag.
Dit proces is traag, maar het weerspiegelt de werkelijkheid veel beter dan analysedashboards.
De opkomst van AI-tools voor zichtbaarheid en het bijhouden van citaties
Een nieuwe categorie van SEO-tools ontstaat om dit probleem op te lossen.
Deze platforms monitoren grote aantallen prompts via meerdere AI-systemen en registreren welke merken en URL's worden genoemd. Ze volgen veranderingen in de frequentie van vermeldingen, vergelijken de zichtbaarheid met die van concurrenten en identificeren welke pagina's standaardbronnen worden.
Hoewel het nog vroeg is, vertegenwoordigen deze tools de toekomst van AI-gebaseerde SEO-meting.
SEO-specialisten kunnen voor het eerst de zichtbaarheid meten, zelfs als er geen klikken plaatsvinden.
In een wereld waarin AI centraal staat, wordt dit type tracking belangrijker dan zoekwoordranglijsten.
Het volgen van merkaanwezigheid in AI-systemen
Merkbewaking is een andere effectieve indicator.
Zodra een entiteit als betrouwbaar wordt beschouwd, hebben AI-systemen de neiging deze te hergebruiken voor veel gerelateerde zoekopdrachten. Door merkvermeldingen, auteursvermeldingen en domeincitaten binnen AI-interfaces te volgen, kunt u inschatten hoe wijdverspreid uw content de antwoorden beïnvloedt.
Dit is met name waardevol voor het meten van de groei in gezag.
Een toenemend aantal vermeldingen duidt er doorgaans op dat de naamsbekendheid van uw entiteit groeit.
De nieuwe statistieken die ertoe doen in LLM SEO
Bij AI-zoekopdrachten wordt succes niet langer uitsluitend bepaald door het aantal bezoekers.
De meest betekenisvolle indicatoren zijn hoe vaak uw site wordt geciteerd, hoe vaak uw merk in antwoorden verschijnt, hoeveel zoekopdrachten uw content tonen en of dezelfde pagina's in meerdere zoekopdrachten worden hergebruikt.
Deze statistieken zijn niet opgenomen in GA4.
Maar zij bepalen wel wie de zichtbaarheid in AI-zoekresultaten beheert.
Waarom vroegtijdige meting een concurrentievoordeel oplevert
Omdat de meeste websites nog steeds geen rekening houden met AI-zichtbaarheid, behalen early adopters een groot voordeel.
Ze leren welke formaten de voorkeur genieten, welke onderwerpen tot citaties leiden en welke pagina's langdurige bronnen worden. Deze gegevens worden direct gebruikt bij de contentstrategie en de selectie van onderwerpen.
Na verloop van tijd verwerven deze sites een stevige positie binnen AI-zoeksystemen, die concurrenten moeilijk kunnen verdringen.
Bij AI-zoekopdrachten is de toeschrijving gebrekkig.
Maar de invloed neemt toe.
En de websites die als eerste leren hoe ze dit moeten meten, zullen later de zichtbaarheid kunnen beheersen.
Veelvoorkomende misvattingen over SEO voor LLM-studenten
Omdat LLM SEO nieuw is, heerst er nog veel onduidelijkheid over.
Veel van wat er tegenwoordig circuleert, is ofwel te simplistisch, verouderd of gebaseerd op aannames die zijn overgenomen uit traditionele SEO. Deze mythes vertragen de acceptatie en zorgen ervoor dat veel websites in de verkeerde richting optimaliseren.
Het is net zo belangrijk om te begrijpen wat niet waar is als om te begrijpen wat wel waar is.
Mythe 1: "SEO is dood door AI"
Dit is de meest voorkomende en meest schadelijke misvatting.
AI-zoekopdrachten maken SEO niet overbodig. Ze zijn er juist van afhankelijk.
Grote taalmodellen doorzoeken het web niet zelfstandig op grote schaal. Ze zijn sterk afhankelijk van zoekmachine-indexen, ophaalsystemen en rankingprocessen die gebouwd zijn op de klassieke SEO-infrastructuur. Als een pagina niet vindbaar, indexeerbaar en geloofwaardig is in zoekmachines, zal deze ook niet in AI-antwoorden verschijnen.
Wat veranderd is, is niet het belang van SEO, maar de resultaten die het oplevert.
In plaats van links te rangschikken, beïnvloedt SEO nu welke bronnen de antwoorden genereren.
SEO is niet verdwenen.
Het is stroomopwaarts van AI gekomen.
Mythe 2: “Backlinks doen er niet meer toe”
Backlinks zijn nog steeds belangrijk.
Ze blijven een van de sterkste indicatoren van vertrouwen en autoriteit binnen zoeksystemen.
Wat veranderd is, is de manier waarop ze worden geïnterpreteerd.
In klassieke SEO hadden links vooral invloed op de ranking. In LLM SEO bepalen links of een bron betrouwbaar genoeg is om überhaupt te worden geraadpleegd en geciteerd. Ze dragen ook bij aan citatiegrafieken die AI-systemen gebruiken om te bepalen welke bronnen centraal staan binnen een onderwerp.
Links zijn echter niet langer het enige signaal dat de reputatie meet.
Merkvermeldingen, verwijzingen naar uitgevers en associaties met entiteiten spelen nu een even belangrijke rol.
Backlinks zijn nog steeds nodig.
Ze zijn op zichzelf niet langer voldoende.
Mythe 3: "Alleen een schema kan je een hoge positie in AI-zoekresultaten opleveren"
Gestructureerde data is krachtig, maar het is geen snelle oplossing.
Schema helpt AI-systemen uw content te begrijpen. Het verbetert classificatie, disambiguatie en entiteitsherkenning. Maar het vervangt de autoriteit niet.
Een zwakke of onbetrouwbare website met perfecte markup zal zelden worden geciteerd.
Bij concurrerende zoekopdrachten fungeert het schema als doorslaggevende factor, niet als primaire rankingfactor. Het vergroot de kans dat een sterke pagina wordt geselecteerd. Het redt een zwakke pagina niet.
LLM SEO is nog steeds in de kern gebaseerd op vertrouwen.
Opmaak helpt het systeem bij het lezen.
Het zorgt er niet voor dat het systeem het gelooft.
Mythe 4: “LLM’s gebruiken alleen oude trainingsgegevens”
Deze mythe komt voort uit een misvatting over hoe moderne AI-systemen werken.
Hoewel trainingsdata algemene kennis verschaffen, vertrouwen de meeste AI-zoekplatformen sterk op realtime ophalen van feitelijke en technische gegevens. Ze halen documenten uit zoekindexen, rangschikken ze en extraheren passages in realtime.
Daarom verschijnen nieuwe pagina's in AI-antwoorden vaak al binnen enkele dagen na publicatie.
Dat is ook de reden waarom actualiteit belangrijker is bij LLM SEO dan bij klassieke SEO.
Training legt de basis.
Het ophalen van gegevens bepaalt de zichtbaarheid.
Mythe 5: "Klikken doen er helemaal niet meer toe"
Klikken zijn minder belangrijk dan vroeger.
Maar ze zijn niet irrelevant.
In veel systemen voedt gebruikersgedrag nog steeds feedbackloops. Bronnen die consequent nuttige antwoorden opleveren, worden vaker geselecteerd. Pagina's die leiden tot een slechte gebruikerservaring worden geleidelijk minder belangrijk geacht.
Wat er veranderd is, is dat klikken niet langer de belangrijkste succesindicator zijn.
Invloed wordt tegenwoordig vaak uitgeoefend zonder fysiek bezoek.
Maar betrokkenheid blijft de basis voor vertrouwen op de lange termijn.
Mythe 6: “Alleen grote merken kunnen winnen met AI-zoekopdrachten”
Grote merken hebben een voordeel, maar ze hebben geen monopolie.
AI-systemen geven sterk de voorkeur aan autoriteit op een bepaald onderwerp.
Een kleinere website die consistent publiceert, een onderwerp grondig behandelt en citaties van gerenommeerde bronnen verkrijgt, kan een dominante speler binnen een niche worden.
In veel technische en opkomende vakgebieden zijn de meest geciteerde AI-bronnen geen grote uitgevers.
Het betreft gespecialiseerde blogs, documentatiesites en individuele experts.
De beperking zit hem niet in de grootte.
Het is een expertise die op lange termijn wordt volgehouden.
Mythe 7: “LLM SEO is gewoon traditionele SEO met een nieuwe naam”
Dit is gedeeltelijk waar en grotendeels onjuist.
LLM SEO bouwt voort op traditionele SEO.
Maar het optimalisatiedoel is anders.
In plaats van te optimaliseren voor rankings, optimaliseer je voor vindbaarheid en citatie. In plaats van pagina's te optimaliseren, optimaliseer je entiteiten. In plaats van klikken te optimaliseren, optimaliseer je invloed.
De basisprincipes blijven hetzelfde.
Het doel is veranderd.
Waarom deze mythen blijven bestaan
De meeste van deze mythes bestaan omdat AI-zoekmachines zich sneller ontwikkelen dan openbare documentatie.
Platformen leggen zelden uit hoe hun systemen werken.
SEO's vullen de leemte op met aannames.
En vroege experimenten worden vaak te snel gegeneraliseerd.
Daardoor negeren veel websites LLM SEO volledig of kiezen ze voor tactieken die er niet toe doen.
Beide benaderingen zijn kostbaar.
De toekomst van SEO in een AI-gedreven wereld
SEO verdwijnt niet:
Het verandert op structureel niveau. Zoekmachines rangschikken niet langer alleen documenten. Ze genereren antwoorden, synthetiseren bronnen en bepalen welke merken de beslissingen van gebruikers beïnvloeden nog voordat er een klik plaatsvindt. In dit nieuwe model is zichtbaarheid belangrijker dan positie.
De eerste grote verandering is van pagina's naar entiteiten:
AI-systemen organiseren het web steeds meer rond merken, auteurs, bedrijven en concepten in plaats van URL's. Websites die er niet in slagen een duidelijke identiteit te creëren, zullen moeite hebben om in de AI-resultaten te verschijnen, zelfs als de inhoud technisch sterk is.
De tweede verschuiving gaat van verkeer naar invloed:
Bij AI-zoekopdrachten bezoeken veel gebruikers nooit een website. Ze consumeren informatie binnen de interface en gaan verder. Dit betekent dat het meest waardevolle resultaat niet langer een klik is, maar de bron die het systeem voldoende vertrouwt om te citeren.
De contentstrategie verandert mee:
In plaats van zich te richten op geïsoleerde zoekwoorden, bouwen succesvolle websites dichte themaclusters op, publiceren ze handleidingen in naslagstijl en onderhouden ze dynamische documenten die actueel blijven naarmate modellen worden bijgewerkt. Autoriteit komt voort uit volledigheid en consistentie, niet uit kwantiteit.
Technische SEO blijft de basis:
AI-systemen zijn nog steeds afhankelijk van crawl-, indexerings- en ophaalprocessen die gebouwd zijn op de infrastructuur van zoekmachines. Websites die prestaties, toegankelijkheid en gestructureerde data negeren, zullen nooit de ophaalfase bereiken, hoe goed de teksten ook zijn.
De meting wordt als volgt bijgewerkt:
Ranglijsten en sessies zullen niet langer de werkelijke impact weergeven. Nieuwe meetmethoden, gebaseerd op citaties, zichtbaarheid van entiteiten en snelle berichtgeving, zullen de belangrijkste indicatoren voor succes worden. Invloed zal verkeer vervangen als de belangrijkste KPI.
Het grootste voordeel is weggelegd voor degenen die er vroeg bij zijn:
AI-zoekmachines zijn nog bezig met het ontwikkelen van hun voorkeuren en standaardbronnen voor zoekresultaten. Websites die nu autoriteit verwerven, zullen in de toekomst duizenden keren opnieuw worden gebruikt voor zoekopdrachten. Nieuwkomers zullen het moeilijk vinden om de gevestigde partijen van die posities te verdringen.
In een wereld waarin AI centraal staat, komt SEO vóór de besluitvorming te staan:
De merken die antwoorden formuleren, zullen de markten vormgeven. En de websites die vandaag leren hoe ze moeten optimaliseren voor vindbaarheid, betrouwbaarheid en entiteiten, zullen morgen de zichtbaarheid bepalen.
Hoe begin je vandaag nog met LLM SEO?
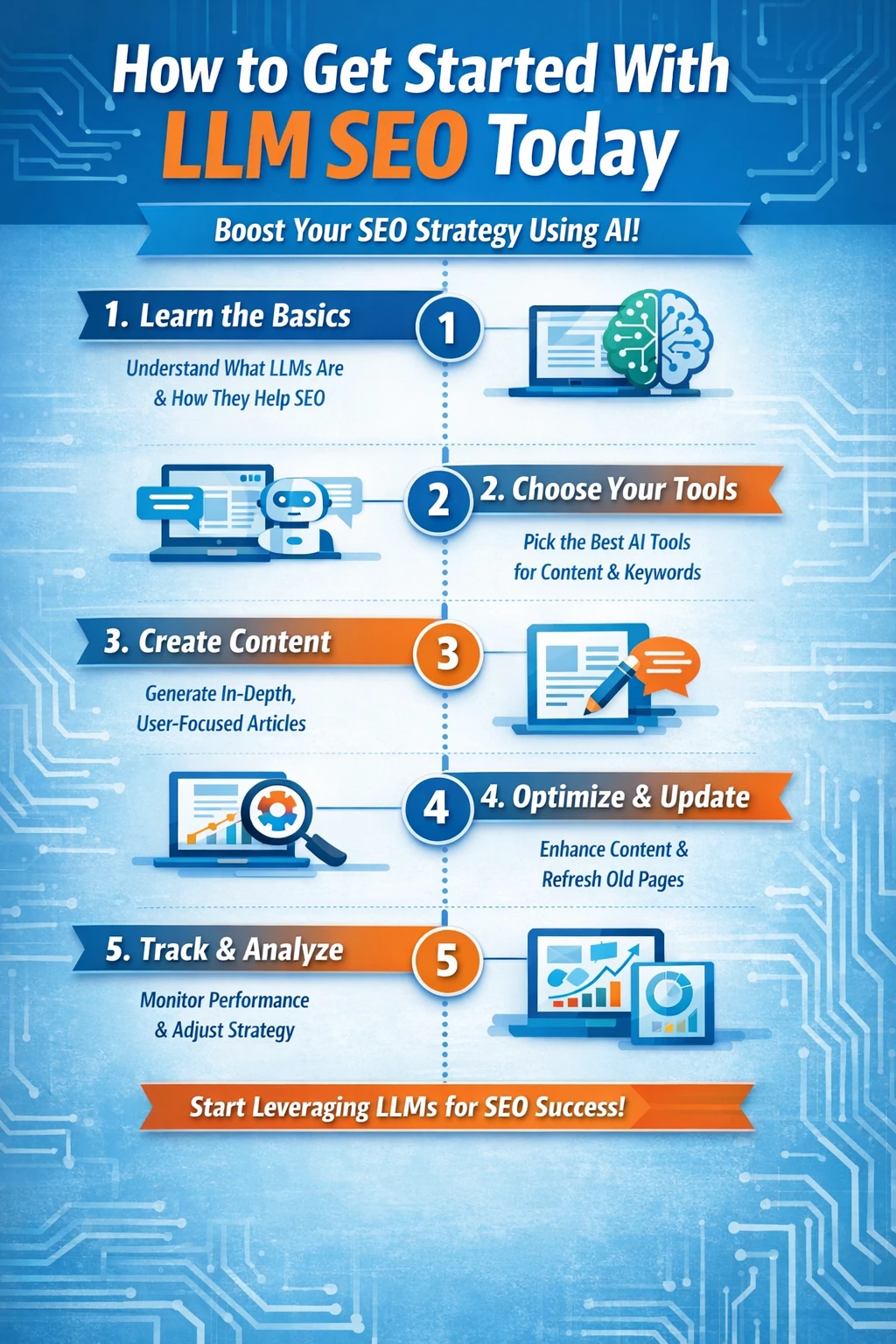
Het beste moment om je voor te bereiden op AI-zoekopdrachten was twee jaar geleden.
Het op één na beste moment is nu.
LLM SEO staat nog in de kinderschoenen. De meeste websites hebben hun content, structuur of autoriteitsstrategie nog niet aangepast aan AI-zoeksystemen. Dit biedt een zeldzaam voordeel voor websites die snel handelen.
Begin bij de basis:
Zorg ervoor dat uw site technisch in orde is, goed geïndexeerd is en gemakkelijk te crawlen is. Zonder sterke technische SEO werkt niets anders in LLM SEO. Vindbaarheid begint altijd met vindbaarheid.
Bouw vervolgens gerichte expertise op het betreffende onderwerp op:
Kies één onderwerp en behandel het grondig met bijbehorende handleidingen, definities en technische artikelen. AI-systemen belonen consistentie veel meer dan kwantiteit. Eén sterke verzameling berichten is beter dan vijftig losse berichten.
Optimaliseer de manier waarop uw content communiceert:
Plaats de antwoorden vroeg in de tekst. Geef duidelijke definities. Structureer de pagina's zo dat elke sectie op zichzelf kan staan en als een herbruikbaar antwoord kan dienen. Denk minder aan overtuiging en meer aan precisie.
Versterk je identiteit:
Voeg duidelijke auteursvermelding, consistente branding en gestructureerde data toe die uw content koppelt aan daadwerkelijke entiteiten. Publiceer onder stabiele auteursnamen. Bouw een reputatie op die door computers herkend kan worden.
Investeer in zichtbaarheid, niet alleen in rankings:
Houd bij waar uw merk verschijnt in AI-antwoorden. Monitor citaties en vermeldingen. Ontdek welke formats en onderwerpen hergebruik genereren. Verkeer volgt invloed, niet andersom.
Het allerbelangrijkste is om LLM SEO als een systeem te beschouwen:
Autoriteit, structuur, actualiteit, reputatie en governance werken allemaal samen. Websites die slechts één laag optimaliseren, slagen zelden. Websites die het volledige systeem opbouwen, worden de standaardbronnen.
AI-zoekopdrachten vormen geen bedreiging voor SEO.
Dit is de volgende versie.
En de websites die nu veranderen, zullen bepalen hoe zoekmachines de komende tien jaar werken.
Veelgestelde vragen
LLM SEO is het proces waarbij uw website wordt geoptimaliseerd zodat grote taalmodellen zoals ChatGPT, Gemini en Perplexity uw content kunnen vinden, correct begrijpen en gebruiken als bron in door AI gegenereerde antwoorden. In plaats van zich alleen te richten op een hoge ranking in Google, richt LLM SEO zich op selectie en vermelding in AI-antwoorden. Het doel is niet alleen zichtbaarheid in zoekresultaten, maar ook zichtbaarheid binnen de door AI gegenereerde antwoorden zelf.
Traditionele SEO optimaliseert pagina's om hoger te scoren in zoekresultaten en klikken te genereren. LLM SEO optimaliseert content zodat deze kan worden opgehaald, vertrouwd en hergebruikt door AI-systemen. In plaats van te concurreren om rankings, concurreer je om een van de weinige bronnen te worden die een AI-model selecteert bij het genereren van een antwoord. Keywords zijn nog steeds belangrijk, maar autoriteit, entiteiten, structuur en duidelijkheid zijn veel belangrijker.
Nee. LLM SEO vervangt traditionele SEO niet.
AI-zoeksystemen zijn sterk afhankelijk van zoekmachine-indexen, crawling-infrastructuur en ranking-signalen die afkomstig zijn van klassieke SEO. Als uw site niet vindbaar en geloofwaardig is in Google of Bing, zal deze ook niet in AI-resultaten verschijnen. LLM SEO bouwt voort op traditionele SEO en breidt deze uit naar AI-gestuurde zoek- en citatiesystemen.
Moderne AI-zoeksystemen maken gebruik van een combinatie van trainingsdata en realtime zoekopdrachten. Trainingsdata bevatten algemene kennis, maar de meeste feitelijke en technische vragen worden beantwoord via realtime zoekopdrachten in zoekmachine-indexen, eigen crawlers en gelicentieerde bronnen van uitgevers. Wanneer een gebruiker een vraag stelt, haalt het systeem relevante pagina's op, rangschikt deze, extraheert passages en genereert een antwoord op basis van deze bronnen.
Websites worden vaker geciteerd als ze een sterke inhoudelijke autoriteit, een duidelijke structuur en een hoog betrouwbaarheidsniveau laten zien. AI-systemen geven de voorkeur aan pagina's die vragen direct beantwoorden, consistente terminologie gebruiken, duidelijke auteursinformatie bevatten en afkomstig zijn van erkende entiteiten. Vermeldingen van merken, redactionele citaten, gestructureerde data en actuele content vergroten allemaal de kans om als bron te worden geselecteerd.
Schema-opmaak garandeert niet direct citaties, maar verbetert wel aanzienlijk hoe AI-systemen uw content begrijpen. Gestructureerde data helpt bij het classificeren van pagina's, het identificeren van auteurs en organisaties, het valideren van de actualiteit en het verbinden van entiteiten op het web. Bij concurrerende zoekopdrachten is het schema vaak de doorslaggevende factor tussen twee bronnen met gelijke autoriteit.
llm.txt is een voorgestelde standaard waarmee website-eigenaren kunnen bepalen hoe AI-crawlers toegang krijgen tot hun content en deze gebruiken. Het verbetert de ranking of de zichtbaarheid momenteel niet. Het belangrijkste doel is beheer, niet optimalisatie. Het toevoegen van llm.txt kan uw site echter toekomstbestendig maken en duidelijkheid scheppen over de vraag of uw content gebruikt mag worden voor training of retrieval, naarmate de regelgeving en licenties rondom AI zich ontwikkelen.
Ja.
LLM SEO hecht veel waarde aan inhoudelijke expertise boven merkgrootte. Veel AI-systemen citeren nicheblogs, documentatiesites en individuele experts wanneer deze blijk geven van diepgaande en consistente expertise in een specifiek onderwerp. Een kleinere site met gerichte inhoud en sterke citaties kan grote merken overtreffen op het gebied van technische en opkomende onderwerpen.
Het meeste AI-verkeer is niet duidelijk zichtbaar in de analyses, omdat veel gebruikers nooit op een bronlink klikken. Wanneer verkeer wel wordt weergegeven, wordt het vaak verkeerd geclassificeerd als direct of niet toegewezen. De beste manier om de impact van AI vandaag de dag te volgen, is door citaties, merkvermeldingen en zichtbaarheid op AI-platformen te monitoren, in plaats van uitsluitend te vertrouwen op GA4-sessies.
Ja. SEO voor LLM-studenten wordt een essentieel onderdeel van de zoekstrategie.
Naarmate AI-antwoorden de meer traditionele zoekresultaten vervangen, zullen de websites die deze antwoorden vormgeven, de zichtbaarheid, merkperceptie en vraaggeneratie bepalen. Websites die al vroeg autoriteit opbouwen, zullen de standaardbronnen worden die voor duizenden toekomstige zoekopdrachten opnieuw worden gebruikt.

